HTE Batch Modules for Reaction Screening: A Complete Guide for Accelerated Drug Discovery
This article provides a comprehensive overview of High-Throughput Experimentation (HTE) batch modules for chemical reaction screening, tailored for researchers, scientists, and drug development professionals.
HTE Batch Modules for Reaction Screening: A Complete Guide for Accelerated Drug Discovery
Abstract
This article provides a comprehensive overview of High-Throughput Experimentation (HTE) batch modules for chemical reaction screening, tailored for researchers, scientists, and drug development professionals. It covers the foundational principles of HTE batch systems, explores their practical applications in optimizing diverse reactions like Buchwald-Hartwig amination and photoredox chemistry, details advanced troubleshooting and machine-learning-driven optimization strategies, and offers a critical validation against alternative continuous flow approaches. The scope is designed to equip scientists with the knowledge to implement and leverage HTE batch platforms for faster, more efficient discovery and process development in biomedical research.
What are HTE Batch Modules? Core Principles and System Components
Defining High-Throughput Experimentation (HTE) in Chemical Synthesis
High-Throughput Experimentation (HTE) is a technique that enables the parallel execution of large arrays of chemically diverse reactions while requiring significantly less effort and material per experiment compared to traditional methods [1]. In modern organic chemistry and drug discovery, HTE has become a core foundation for reaction discovery, optimization, and understanding reaction scope [2]. This approach allows researchers to systematically interrogate reactivity across diverse chemical spaces, accelerating the development of synthetic methodologies and the identification of optimal conditions for challenging transformations.
The power of HTE lies in its ability to pose comprehensive questions about chemical reactivity and obtain detailed answers through rationally designed experimental arrays. By examining permutations of reaction components including catalysts, ligands, solvents, and reagents, researchers can rapidly identify optimal conditions while simultaneously developing a deeper understanding of how each component influences reaction outcomes [1].
Key Applications and Significance in Drug Discovery
HTE has transformed modern synthetic chemistry, particularly in pharmaceutical research where it addresses critical challenges:
- Reaction Discovery and Optimization: HTE is equally powerful for optimizing individual steps in total synthesis and driving discovery of novel methodology [1]. It enables rapid identification of preferred catalysts, reagents, and solvents for given transformations.
- Material-Efficient Screening: The miniaturization inherent in HTE (typically 0.1-1.0 mg per reaction) allows evaluation of broad condition arrays with limited amounts of precious compounds [2] [1].
- Comprehensive Reaction Understanding: Large arrays explicitly examine combinations of experimental factors, revealing patterns and relationships that would remain hidden with traditional experimentation [1].
- Accelerated Medicinal Chemistry: HTE tools allow project teams to "fail fast," directing them to pursue productive synthetic routes before substantial time and resources are invested [2].
The significance of HTE is particularly evident in drug development, where it has become standard practice in leading pharmaceutical companies. Over 80% of the top 10 largest pharma companies utilize HTE approaches, demonstrating its critical role in modern drug discovery pipelines [3].
Experimental Design and Workflow
Rational Experimental Design
Effective HTE requires carefully constructed experimental arrays that maximize information gain while conserving resources. Unlike traditional experimentation that tests small numbers of conditions sequentially, HTE employs systematic approaches:
- Factor Selection: Key reaction parameters (catalyst, ligand, solvent, base, temperature) are identified based on literature analysis and mechanistic understanding [2] [1].
- Chemical Space Coverage: Solvents and reagents are selected to maximize breadth of chemical space examined, using numerical parameters like dielectric constant and dipole moment to ensure diversity [1].
- Control Inclusion: Arrays include negative controls and experimental replicates to validate results and assess reproducibility [1].
- Dimensional Balancing: When constraints exist, the most influential factors receive the largest array dimensions, while minor factors are assigned smaller dimensions [1].
End-User Plate Systems
A sophisticated HTE implementation involves "end-user plates" – pre-prepared arrays of catalysts and reagents stored under appropriate conditions. Domainex's platform exemplifies this approach [2]:
Table 1: End-User Plate Specifications and Applications
| Plate Type | Reaction Scale | Key Advantages | Ideal Use Cases |
|---|---|---|---|
| μL plate | 0.1-0.5 mg substrate | Minimal material consumption; High-density screening | Precious intermediates; Early discovery |
| mL plate | 1-5 mg substrate | Easier handling; Direct scalability | Route scouting; Process development |
These systems provide significant efficiency: a 24-well Suzuki-Miyaura coupling plate tests 6 palladium pre-catalysts with 2 bases and 2 solvents, delivering comprehensive condition screening with less than one hour of lab work [2].
HTE Workflow Process
The complete HTE process involves multiple interconnected steps from experimental design to data analysis and decision-making [3]:
HTE Workflow Process
Case Study: Suzuki-Miyaura Cross-Coupling Optimization
Experimental Protocol
Objective: Identify optimal conditions for Suzuki-Miyaura cross-coupling of challenging aryl chlorides with boronic acids.
Plate Design: 24-well format with 6 palladium pre-catalysts, 2 bases (K₃PO₄ and Cs₂CO₃), and 2 solvents (t-AmOH/H₂O and 1,4-dioxane/H₂O) [2].
Procedure:
- Plate Preparation: Pre-catalyst solutions in THF are dispensed into glass vials and evaporated to deposit accurate catalyst quantities (performed under inert atmosphere for reproducibility).
- Reagent Addition: Aryl chloride and boronic acid substrates are added as stock solutions (10-50 mM concentration in DMSO or reaction solvent).
- Base/Solvent Addition: Base solutions (0.1 M) in solvent/water mixtures (4:1 ratio) are added via liquid handling.
- Reaction Execution: Plate is sealed and heated to 80-100°C for 12-18 hours with agitation.
- Analysis:
- Quench with acetonitrile containing internal standard (N,N-dibenzylaniline)
- UPLC-MS analysis with 2-minute gradient methods
- Automated data processing using tools like PyParse for peak identification and integration [2]
Data Analysis and Results Interpretation
Quantitative Analysis: Conversion metrics are calculated using "corrP/STD" values: product peak area divided by internal standard peak area, normalized to maximum observed ratio [2]. This approach enables reliable cross-comparison between wells while mitigating UPLC-MS analytical artifacts.
Table 2: Representative Suzuki-Miyaura HTE Results
| Pre-catalyst | Base | Solvent System | Conversion (corrP/STD) | Isolated Yield (%) |
|---|---|---|---|---|
| BrettPhos Pd G3 | K₃PO₄ | t-AmOH/H₂O | 1.00 | 88% |
| RuPhos Pd G3 | Cs₂CO₃ | 1,4-dioxane/H₂O | 0.95 | 82% |
| t-BuXPhos Pd G3 | K₃PO₄ | t-AmOH/H₂O | 0.15 | <5% |
| XPhos Pd G3 | Cs₂CO₃ | 1,4-dioxane/H₂O | 0.98 | 85% |
Key Findings:
- BrettPhos Pd G3 with K₃PO₄ in t-AmOH/H₂O delivered optimal performance (88% isolated yield)
- t-BuXPhos Pd G3 showed substrate-specific incompatibility, highlighting how HTE reveals condition-dependent catalyst performance
- Successful conditions were directly scalable from microgram to multimilligram scale without re-optimization [2]
The Scientist's Toolkit: Essential HTE Components
Research Reagent Solutions
Table 3: Essential HTE Reagents and Equipment
| Component | Function | Examples & Specifications |
|---|---|---|
| Palladium Pre-catalysts | Cross-coupling catalysis | BrettPhos Pd G3, RuPhos Pd G3, XPhos Pd G3; 0.5-2.0 mol% loading [2] |
| Phosphine Ligands | Stabilize active metal centers; Modulate reactivity | Biaryl phosphines (XPhos), alkylphosphines (PCy3), bis-phosphines (dppf) [2] |
| Solvent Systems | Reaction medium; Solubility control | t-AmOH/H₂O, 1,4-dioxane/H₂O, THF, toluene; 4:1 organic/water ratio [2] |
| Base Arrays | Promote transmetalation; Scavenge acids | K₃PO₄, Cs₂CO₃, KOAc; 1.5-3.0 equivalents [2] [1] |
| Analysis Internal Standards | Quantitative UPLC-MS calibration | N,N-dibenzylaniline; 2 µmol as 4 mM DMSO stock [2] |
| HTE Plates & Hardware | Reaction vessels; Heating/agitation | 24-well "end-user" plates (μL and mL scale); Glass vials with sealing mats [2] |
| Software Solutions | Experimental design; Data analysis | AS-Experiment Builder (plate design); AS-Professional (visualization); PyParse (automated UPLC-MS analysis) [2] [3] |
Advanced Statistical Analysis in HTE
The HiTEA Framework
Advanced HTE data analysis employs sophisticated statistical frameworks like the High-Throughput Experimentation Analyzer (HiTEA), which combines three orthogonal approaches [4]:
HiTEA Statistical Framework
Key Statistical Approaches
- Random Forest Analysis: Identifies which reaction variables (catalyst, solvent, base) most significantly impact outcomes without assuming linear relationships [4].
- Z-Score ANOVA-Tukey: Normalizes yields across different substrate classes and identifies statistically significant best-in-class and worst-in-class reagents [4].
- Principal Component Analysis: Visualizes how high-performing and low-performing reagents populate chemical space, revealing clustering and selection biases [4].
This comprehensive statistical framework enables extraction of meaningful chemical insights from complex HTE datasets, moving beyond simple condition identification to fundamental reaction understanding.
Critical Considerations for Successful HTE Implementation
Data Quality and Analysis Challenges
Quantitative HTS (qHTS) presents specific statistical challenges that researchers must address:
- Parameter Estimation Variability: Nonlinear modeling with the Hill equation for concentration-response data produces highly variable parameter estimates when experimental designs fail to establish both asymptotes [5].
- False Positive/Negative Risks: Flat response curves from potent compounds may generate poor fits and be misclassified as inactive, while truly null compounds might spuriously appear active due to random variation [5].
- Measurement Error Impact: Random error significantly diminishes reproducibility of parameter estimates, necessitating experimental replicates and careful error assessment [5].
Implementation Best Practices
- Embrace Comprehensive Data Inclusion: Removal of 0% yielding reactions leads to poorer understanding of reaction classes; both positive and negative data are essential for robust model building [4].
- Address Systematic Error Sources: Well location effects, compound degradation, signal bleaching, and compound carryover can introduce bias that challenges replication [5].
- Utilize Appropriate Software Tools: Vendor-neutral platforms like AS-Experiment Builder streamline plate design, experimental execution, and data visualization while enabling seamless metadata flow [3].
- Validate with Model Substrates: Before deploying project-specific screens, validate HTE designs with known model systems to verify catalyst reactivity in plate-based formats [2].
High-Throughput Experimentation represents a paradigm shift in chemical synthesis, enabling systematic exploration of reaction spaces that were previously inaccessible through traditional methods. By implementing rational experimental designs, leveraging miniaturized platforms, and applying sophisticated statistical analysis, researchers can accelerate reaction optimization and gain fundamental insights into chemical reactivity.
The integration of HTE approaches into drug discovery pipelines has demonstrated significant value in reducing development timelines, conserving precious materials, and building robust synthetic routes. As HTE methodologies continue to evolve and become more accessible, they promise to further transform synthetic chemistry practice across academic and industrial settings.
High-Throughput Experimentation (HTE) has revolutionized reaction screening and optimization in modern research and development, particularly within the pharmaceutical industry. The architecture of a contemporary HTE batch platform is an integrated system comprising three core technological subsystems: automated liquid handlers for precise reagent delivery, parallel batch reactors for controlled reaction execution, and advanced analytics platforms for data processing and insight generation. This integrated approach enables the exploration of vast chemical reaction spaces—encompassing variables such as reagents, solvents, catalysts, and temperatures—in a highly efficient and parallelized manner, moving beyond traditional, resource-intensive one-factor-at-a-time methods [6]. When synergistically combined with machine learning (ML) optimization frameworks like Minerva, these platforms demonstrate robust performance in handling large parallel batches, high-dimensional search spaces, and the experimental noise inherent in real-world laboratories [6]. This document details the architecture, protocols, and data handling of a modern HTE platform, framed within the context of accelerating reaction screening research for drug development professionals.
Core Architectural Subsystems
A modern HTE batch platform is a coordinated system where data and materials flow seamlessly between specialized modules. The architecture is structured to support highly parallel, automated experimentation from initial setup to final analysis.
Automated Liquid Handling Systems
Automated liquid handlers are the workhorses of sample and reagent preparation in HTE. They enable the highly precise and rapid dispensing of reagents into reaction vessels, which is a prerequisite for conducting large-scale screening campaigns with 24, 48, 96, or more parallel reactions. Their primary function is to transform a chemist's digital experimental design into a physical, ready-to-run assay plate. Key capabilities include:
- Miniaturization: Performing reactions at microliter scales to reduce reagent cost and waste.
- Precision and Accuracy: Ensuring reproducible reagent concentrations across all wells.
- Throughput: Rapidly preparing hundreds of reaction combinations per hour.
- Integration: Operating in concert with other robotic systems to transport plates to and from reactor blocks and analytics.
Parallel Batch Reactor Systems
Parallel batch reactors provide the controlled environment where chemical transformations occur. These systems consist of multiple miniature reactors (autoclaves or well-plates) that operate simultaneously under defined conditions. As exemplified by commercial systems, a typical setup may comprise four to eight parallel Hastelloy autoclaves, each with a reactor volume of 300 ml, capable of operating flexibly over a wide pressure and temperature range with excellent comparability [7]. These systems are designed to generate high-quality, scalable data, making them indispensable for evaluating catalysts, synthesizing battery materials, and conducting polymerization applications [7]. Critical features include:
- Parallelization: Simultaneous execution of 4 to 96+ reactions.
- Environmental Control: Precise regulation of temperature, pressure, and stirring for each reactor.
- Material Compatibility: Construction from chemically resistant materials like Hastelloy to withstand diverse reaction conditions.
- Modularity: Configurations that can include reactors dedicated to different modes, such as separate reaction and catalyst activation lines [7].
Data Analytics and Machine Intelligence
The data generated by HTE campaigns is vast and complex, necessitating a sophisticated analytics layer to transform raw results into actionable insights. This layer relies on a modern data platform architecture that manages the entire lifecycle of data, from ingestion to analysis [8]. Machine learning frameworks, particularly those based on Bayesian optimization, are central to this layer. They guide experimental design by balancing the exploration of unknown reaction spaces with the exploitation of promising conditions identified from prior data [6]. The core functions of this subsystem are:
- Data Ingestion and Storage: Automatically collecting data from analytical instruments and storing it in scalable cloud data lakes or warehouses [8].
- Data Processing: Cleaning, formatting, and transforming raw data into a usable format for analysis.
- Machine Learning-Guided Optimization: Using algorithms like Gaussian Process regressors and acquisition functions (e.g., q-NParEgo, TS-HVI) to select the most informative next batch of experiments for multi-objective optimization (e.g., yield and selectivity) [6].
- Visualization and Reporting: Providing dashboards and tools for researchers to interact with the data, track campaign progress, and make decisions.
Table 1: Key Quantitative Performance Metrics from an ML-Driven HTE Optimization Campaign [6]
| Optimization Metric | Performance Data | Context and Significance |
|---|---|---|
| Batch Size | 96-well plates | Standard for solid-dispensing HTE workflows; enables high parallelism [6] |
| Search Space Complexity | 88,000 conditions; 530 dimensions | Demonstrates capability to navigate high-dimensional spaces [6] |
| Optimization Outcome (Ni-catalyzed Suzuki) | 76% AP yield, 92% selectivity | Outperformed chemist-designed HTE plates for a challenging transformation [6] |
| Pharmaceutical Process Optimization | >95% AP yield & selectivity for API syntheses | Identified high-performing, scalable conditions for Ni-Suzuki and Pd-Buchwald-Hartwig reactions [6] |
| Development Timeline Acceleration | 4 weeks vs. 6 months | ML framework drastically reduced process development time compared to a prior campaign [6] |
Integrated Experimental Workflow
The power of a modern HTE platform lies in the seamless integration of its subsystems into a coherent, iterative workflow. This workflow closes the loop between experimental design, execution, and data analysis.
Detailed Experimental Protocol: ML-Driven Reaction Optimization
This protocol outlines a specific application of the HTE platform for optimizing a chemical reaction using a machine learning-guided approach, as validated in recent literature [6].
Protocol Title: ML-Guided Optimization of a Nickel-Catalyzed Suzuki Reaction in a 96-Well HTE Format
4.1.1 Background and Objective The objective is to identify optimal reaction conditions for a nickel-catalyzed Suzuki coupling, a challenging transformation relevant to pharmaceutical synthesis, by maximizing Area Percent (AP) yield and selectivity. The protocol leverages the Minerva ML framework to efficiently navigate a large search space of ~88,000 potential conditions [6].
4.1.2 Research Reagent Solutions and Materials
Table 2: Essential Research Reagents and Materials for Ni-Catalyzed Suzuki HTE Campaign
| Reagent/Material | Function/Purpose | Example/Note |
|---|---|---|
| Nickel Catalyst Precursors | Non-precious metal catalysis center | Earth-abundant alternative to Pd, aligning with cost and sustainability goals [6]. |
| Ligand Library | Modulates catalyst activity and selectivity | A diverse set of phosphine and nitrogen-based ligands is typically screened. |
| Aryl Halide Substrate | Electrophilic coupling partner | Varies based on specific reaction target. |
| Boronated Substrate | Nucleophilic coupling partner | e.g., Aryl boronic acid or ester. |
| Base Library | Facilitates transmetalation step | e.g., Carbonates, phosphates. |
| Solvent Library | Reaction medium | Selected from a range of common solvents (e.g., THF, 1,4-dioxane, DMF), adhering to pharmaceutical solvent guidelines where possible [6]. |
| 96-Well Reaction Plate | Miniaturized reaction vessel | Compatible with liquid handler and reactor block. |
4.1.3 Step-by-Step Procedure
Reaction Space Definition:
- Define the discrete combinatorial set of plausible reaction conditions. This includes selecting specific members for each variable category: catalyst, ligands, solvents, bases, and continuous variables like concentration and temperature.
- Apply chemical knowledge and practical constraints (e.g., solvent boiling point, unsafe reagent combinations) to filter out impractical conditions automatically [6].
Initial Experimental Batch (Iteration 1):
- Utilize algorithmic quasi-random Sobol sampling to select an initial batch of 96 reaction conditions. This strategy maximizes the coverage of the reaction space, increasing the likelihood of discovering informative regions [6].
- The ML framework outputs a digital experimental design file listing the specific condition for each well in the 96-well plate.
Reaction Plate Preparation (Liquid Handling):
- Program the automated liquid handler with the experimental design file.
- The robot precisely dispenses the appropriate stock solutions of substrates, catalyst, ligands, base, and solvent into each well of the 96-well plate according to the specified concentrations and volumes.
Reaction Execution (Batch Reactor):
- Transfer the sealed 96-well plate to a parallel batch reactor system capable of maintaining a uniform temperature across all wells.
- Initiate the reactions and allow them to proceed for the set reaction time.
Quenching and Analysis (Liquid Handler & Analytics):
- After the reaction time has elapsed, use the liquid handler to add a quenching agent to each well to stop the reaction.
- Prepare samples from each well for analysis, typically by UPLC or HPLC, using the liquid handler for dilution and transfer to analysis vials or plates.
- Analyze the samples. The analytical software will output data files containing metrics like Area Percent (AP) yield and selectivity for each reaction.
Data Processing and ML Model Update:
- Ingest the raw analytical results into the central data platform (e.g., using a tool like Airbyte for data integration) [9] [8].
- The ML framework (Minerva) automatically retrieves the structured data. A Gaussian Process (GP) regressor is trained on all accumulated experimental data to predict reaction outcomes and their uncertainties for all possible conditions in the predefined space [6].
Next-Batch Selection:
- A multi-objective acquisition function (e.g., q-NParEgo, TS-HVI) evaluates all possible conditions, balancing the exploration of uncertain regions with the exploitation of known high-performing conditions [6].
- The function selects the next batch of 96 conditions predicted to provide the most information for progressing towards the optimization objectives (high yield and selectivity).
Iteration:
- Repeat steps 3 through 7 for the newly selected batch of experiments.
- Continue this iterative process until convergence is achieved (i.e., no significant improvement is observed), the optimization objectives are met, or the experimental budget is exhausted.
4.1.4 Data Analysis and Interpretation
- The primary metric for evaluating optimization performance is the hypervolume metric. This calculates the volume in objective space (e.g., yield vs. selectivity) enclosed by the set of conditions found by the algorithm, measuring both convergence towards the optimum and the diversity of solutions [6].
- Compare the final hypervolume achieved by the ML-driven campaign against a baseline (e.g., traditional chemist-designed grid search) or the theoretical maximum.
Table 3: Example Quantitative Outcomes from an ML-Driven HTE Campaign for API Synthesis [6]
| Reaction Type | Key Optimization Objectives | Reported Outcome | Development Impact |
|---|---|---|---|
| Ni-catalyzed Suzuki Coupling | Maximize Yield and Selectivity | Multiple conditions with >95% AP yield and selectivity | Identified viable, low-cost metal catalysis route. |
| Pd-catalyzed Buchwald-Hartwig Amination | Maximize Yield and Selectivity | Multiple conditions with >95% AP yield and selectivity | Accelerated process development for an API. |
| Pharmaceutical Process (unspecified) | Identify scalable process conditions | Improved conditions at scale identified in 4 weeks | Reduced development time from a previous 6-month campaign [6]. |
The Scientist's Toolkit: Essential Software and Data Solutions
The effective operation of an HTE platform relies on a suite of software tools for data management, statistical analysis, and machine learning.
Table 4: Key Quantitative Analysis and Data Tools for HTE Research
| Tool / Solution | Primary Function in HTE | Key Features for HTE Workflows |
|---|---|---|
| Python (Custom ML Frameworks, e.g., Minerva) | Core ML-guided optimization | Bayesian optimization (Gaussian Processes), scalable acquisition functions (q-NParEgo, TS-HVI), handling of categorical variables [6]. |
| R / RStudio | Statistical analysis and data visualization | Advanced statistical testing, custom graphics (ggplot2), extensive packages for data analysis; ideal for in-depth exploration of HTE results [9]. |
| JMP | Interactive visual data exploration and DOE | Design of Experiments (DOE) capabilities, point-and-click interface for visual data exploration, dynamic modeling [9]. |
| Airbyte | Data ingestion and integration | Syncs data from hundreds of sources (e.g., analytical instruments, LIMS) into a central data platform, automating data pipeline creation [9]. |
| Modern Data Platform (Architecture) | Holistic data management | Manages data lifecycle: Ingestion, Storage, Processing, Access, Pipelines, and Governance, ensuring data is usable and trustworthy [8]. |
| MAXQDA / NVivo | Analysis of qualitative experimental notes | AI-assisted coding of researcher observations or free-text notes; supports mixed-methods analysis when combined with quantitative HTE data [9]. |
The architecture of a modern HTE batch platform represents a paradigm shift in chemical reaction screening. By integrating highly automated liquid handlers, parallelized batch reactors, and a sophisticated, ML-driven analytics layer, these platforms enable researchers to navigate complex chemical landscapes with unprecedented speed and intelligence. The detailed protocol and data presented herein demonstrate the practical application of this architecture, culminating in the rapid identification of high-performing reaction conditions for challenging transformations like nickel-catalyzed cross-couplings. This integrated, data-centric approach is indispensable for accelerating research timelines in drug development and beyond.
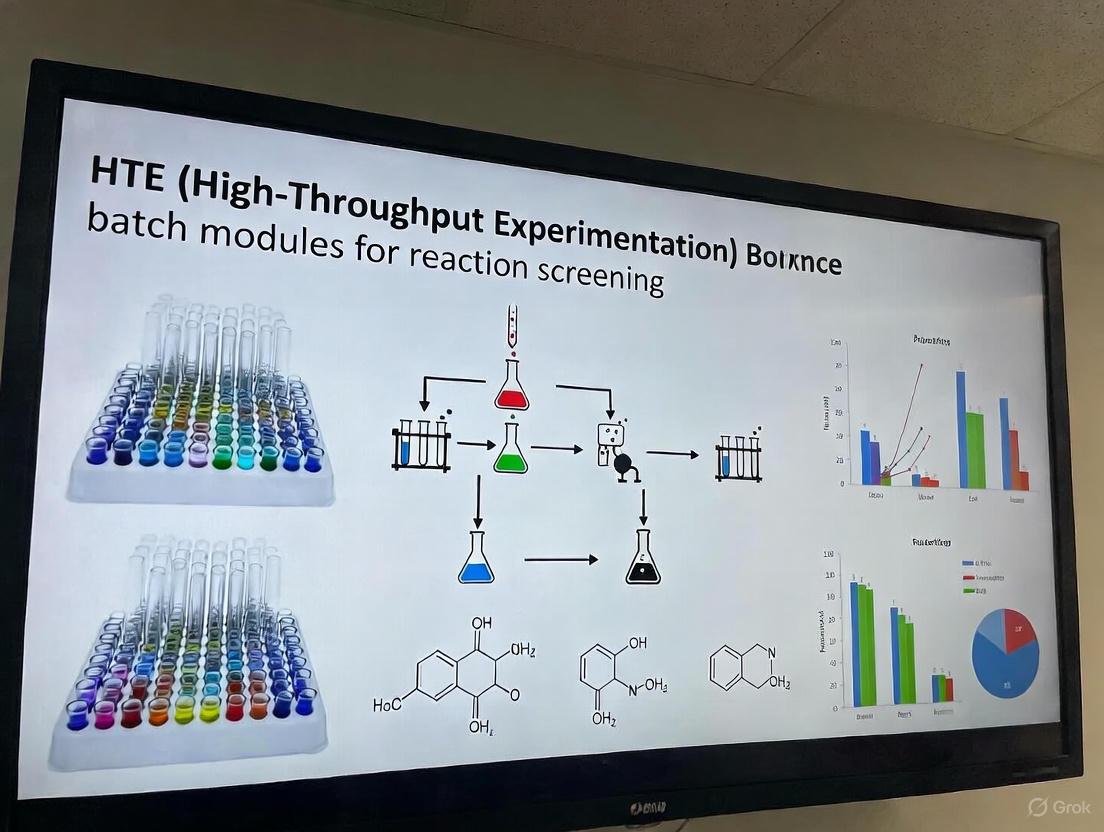
In modern reaction screening research, High-Throughput Experimentation (HTE) has become indispensable for accelerating discovery and optimization in fields ranging from pharmaceutical development to materials science. At the core of any HTE workflow are multiwell plates, which serve as standardized reaction vessels enabling the parallel execution of hundreds to thousands of microscopic experiments. The migration from traditional single-run batch reactors to miniaturized, parallelized systems in 96, 384, and 1536-well formats represents a paradigm shift in chemical and biological research methodology. These platforms provide the foundational structure for automating reagent addition, mixing, temperature control, and analysis, thereby dramatically increasing experimental efficiency while reducing reagent consumption and waste generation. This application note details the practical implementation of multiwell plates as reaction vessels within HTE batch modules, providing researchers with standardized protocols and critical technical specifications to enable robust, reproducible screening campaigns.
Technical Specifications and Comparative Analysis
The physical and functional characteristics of multiwell plates directly determine their suitability for specific HTE applications. Adherence to international standards ensures compatibility with automated handling systems, liquid dispensers, and detection instrumentation across platforms from various manufacturers.
Standardized Microplate Dimensions
All standard microplates conform to the ANSI/SLAS standards, ensuring dimensional uniformity for automated compatibility. The standard footprint for microplates is 127.76 mm in length by 85.48 mm in width, with variations in height and internal well geometry defining the different well formats [10] [11]. This consistency allows the same plate to be used across different instruments and robotic platforms within an automated workflow. The following table summarizes the key dimensional parameters for common plate formats used in HTE.
Table 1: Physical Dimensions of Standard Multiwell Plate Formats
| Parameter | 96-Well Plate | 384-Well Plate | 1536-Well Plate |
|---|---|---|---|
| Total Wells | 96 | 384 | 1536 |
| Well Layout (Rows x Columns) | 8 x 12 | 16 x 24 | 32 x 48 |
| Standard Well-to-Well Spacing (mm) | 9.00 | 4.50 | 2.25 |
| Well Volume (µL) | ~350 [11] | ~105 [11] | ~12 [11] |
| Recommended Working Volume (µL) | 80-350 [11] | 24-90 [11] | 4-12 [11] |
| Common Well Bottom Types | F-, U-, V-, C-Bottom [10] | F-Bottom | F-Bottom |
Working Volume and Well Geometry
The choice of well format is primarily dictated by the required reaction scale and the available detection sensitivity. The progressive miniaturization from 96-well to 1536-well formats enables significant resource savings.
Table 2: Well Geometry and Volume Capacity
| Format | Well Diameter (mm) | Well Depth (mm) | Max Volume (µL) | Typical HTE Reaction Volume |
|---|---|---|---|---|
| 96-Well | ~7.15 [11] | ~10.80 [11] | ~400 [11] | 50-200 µL |
| 384-Well | ~3.65 [11] | ~10.40 [11] | ~105 [11] | 20-50 µL |
| 1536-Well | ~1.70 [11] | ~4.80 [11] | ~12 [11] | 5-10 µL |
The geometry of the well bottom (e.g., flat, round, or conical) is a critical consideration. Flat-bottom (F-bottom) wells are optimal for optical detection methods like absorbance or fluorescence, while round-bottom (U or V-bottom) wells are superior for facilitating efficient mixing of small liquid volumes and minimizing dead volume during liquid handling [10].
Experimental Protocols for HTE Reaction Screening
The following protocols provide a framework for executing chemical reaction screens across different multiwell plate formats, with an emphasis on reproducibility and integration with automated systems.
Protocol: General Workflow for Reaction Setup in 96-Well Plates
This protocol is designed for screening reaction conditions where reagent consumption is not a primary constraint, offering a balance between ease of handling and throughput.
Research Reagent Solutions & Materials
- Multiwell Plate: 96-well, polypropylene, U-bottom (for mixing) or F-bottom (for optical analysis) [11].
- Plate Seal: Adhesive aluminum foil or heat-sealing film to prevent solvent evaporation and cross-contamination.
- Liquid Handler: Automated pipetting system or manual multi-channel pipette.
- Platform Shaker: Orbital shaker capable of accommodating microplates (e.g., Teleshake, 100-2000 rpm) [12].
- Heating/ Cooling Incubator: For temperature-controlled reactions (e.g., thermal cycler, shaking incubator) [13].
Procedure
- Plate Layout Design: Map the reaction conditions on a plate template. Assign controls (positive, negative, solvent blanks) to specific wells, typically in the first and last columns.
- Reagent Dispensing:
- Use an automated liquid handler to dispense solvents and stock solutions of substrates into the designated wells. A typical final volume for a 96-well screen is 100-150 µL.
- Pre-dispense reagents sensitive to air or moisture in an inert atmosphere glove box if required.
- Reaction Initiation: Using the liquid handler, rapidly add the catalyst or initiating reagent solution across all wells to start the reactions simultaneously.
- Sealing: Immediately apply a pierceable, adhesive seal to the plate to prevent evaporation.
- Mixing and Incubation:
- Place the sealed plate on an orbital microplate shaker. Mix at 500-1500 rpm for 1-2 minutes to ensure homogeneity [12].
- Transfer the plate to a pre-heated/cooled incubator or thermal cycler set to the desired reaction temperature (e.g., 25°C, 60°C). Incubate for the specified duration.
- Reaction Quenching: After the incubation period, add a quenching solution (e.g., acid, base, or a scavenger resin) to all wells via the liquid handler.
- Analysis: Centrifuge the plate briefly to collect condensation. Remove the seal and either proceed with in-plate analysis (e.g., UV-Vis, fluorescence) or transfer aliquots to analysis vials or plates for LC-MS, GC-MS, or other offline methods.
Protocol: Miniaturized Screening in 384-Well and 1536-Well Formats
This protocol is for ultra-high-throughput applications where reagent conservation and maximum data point generation are critical.
Research Reagent Solutions & Materials
- Multiwell Plate: 384-well or 1536-well, polypropylene, F-bottom (optically clear for detection) [11].
- Non-Volatile Seal: Optically clear, adhesive seal.
- Nano-Liter Liquid Handler: Acoustic dispenser or positive-displacement nano-dispenser capable of handling µL to nL volumes accurately.
- High-Frequency Microplate Shaker: e.g., Teleshake 1536, capable of frequencies up to 8500 rpm for effective mixing of sub-microliter volumes [14].
- Microplate Centrifuge: With a rotor adapted for high-density plates.
- Microplate Reader: Compatible with 384/1536-well formats for high-throughput absorbance, fluorescence, or luminescence detection [13].
Procedure
- Plate Layout and Dispensing:
- Design a dense, randomized condition layout using specialized software.
- Use a nano-liter liquid handler to transfer substrates and reagents directly into the wells. Typical final volumes are 20-50 µL for 384-well and 5-10 µL for 1536-well plates [11].
- Initiation and Sealing: Initiate reactions by dispensing the smallest volume component (e.g., catalyst) across the plate. Seal immediately with an optically clear film.
- Mixing and Incubation:
- Mix the sealed plate on a high-frequency shaker (e.g., 4000-8500 rpm for 1-5 minutes) to overcome high surface tension in low-volume wells [14].
- Incubate at the target temperature in a thermally calibrated incubator. Due to the high surface-to-volume ratio, evaporation control is critical; ensure seals are properly applied.
- Quenching and Analysis:
- Quench reactions by adding a small volume of quenching solution.
- For colorimetric or fluorometric assays, analyze the plate directly in a microplate reader [13].
- For MS-based analysis, dilute reaction mixtures with a compatible solvent and use an automated system to inject from the plate.
The Scientist's Toolkit: Essential Research Reagent Solutions and Materials
Successful HTE relies on a suite of specialized tools and reagents designed for miniaturization and automation.
Table 3: Essential Materials for HTE with Multiwell Plates
| Item | Function/Description | Key Consideration for HTE |
|---|---|---|
| Polypropylene Plates | Chemically resistant workhorse for most synthetic chemistry applications [15]. | Withstands a wide temperature range and is resistant to many organic solvents. Ideal for storage and reaction setup. |
| Polystyrene Plates | Optically superior material for direct photometric assays [15]. | Check chemical resistance; not compatible with many organic solvents (e.g., acetone, DMSO, ethyl acetate) [16]. |
| Adhesive Seals | Seals plate to prevent evaporation and contamination during incubation and shaking. | Choose pierceable seals for reagent addition or optical clear seals for in-plate detection. |
| Automated Liquid Handler | Dispenses reagents with high precision and reproducibility across all wells. | Capabilities range from µL-handling for 96-well to nL-handling for 1536-well formats. |
| Microplate Shaker | Ensures homogenous mixing of reaction components. | Orbital pattern is standard. Higher frequencies (≥4000 rpm) are needed for 1536-well formats [14] [12]. |
| Microplate Reader | Provides high-throughput endpoint analysis via absorbance, fluorescence, or luminescence. | Must be compatible with the plate format and have the appropriate wavelength filters/detectors for the assay [13]. |
Workflow and Material Compatibility Visualization
Implementing a robust HTE workflow requires careful planning of the experimental sequence and a clear understanding of material compatibility. The following diagrams illustrate the logical flow of a screening campaign and the critical decision points for selecting appropriate reaction vessels.
HTE Screening Workflow
Diagram 1: HTE Screening Workflow. This diagram outlines the standard sequence of operations for a high-throughput reaction screen, highlighting the plate format selection as a critical initial decision that influences all subsequent steps.
Material Compatibility Selection
Diagram 2: Material Selection Guide. A decision tree to guide the selection between polypropylene and polystyrene plates based on the chemical and physical demands of the experiment, highlighting the need to verify chemical compatibility for polystyrene [16].
High-Throughput Experimentation (HTE) using batch modules has become a cornerstone of modern research and development in chemistry and pharmacology. By allowing numerous reactions to be conducted simultaneously under varied conditions, HTE enables a rapid and systematic exploration of complex chemical spaces. This approach is particularly powerful when integrated with machine learning (ML) algorithms, which guide experimental design towards optimal outcomes. This document details the key advantages of HTE batch systems, focusing on their capacity for parallelization, their ability to facilitate the efficient exploration of categorical variables, and their inherent cost-effectiveness. Framed within the context of reaction screening research, the following sections provide quantitative data, detailed protocols, and visual workflows to illustrate these core benefits.
Key Advantages and Data Presentation
HTE batch modules fundamentally accelerate research by parallelizing experiments and efficiently navigating the high-dimensional parameter spaces common in chemical synthesis. The quantitative impact of these advantages is summarized in the tables below.
Table 1: Throughput and Efficiency of HTE Platforms. This table compares different HTE configurations, highlighting their experimental throughput and primary applications [6] [17] [18].
| HTE Platform / Configuration | Typical Parallel Batch Size | Key Efficiency Metrics | Primary Applications / Advantages |
|---|---|---|---|
| Standard HTE Batch Module | 16 - 48 reactors [19] | High comparability, high-quality scalable data [19]. | Catalyst testing & optimization (gas phase, synthesis gas) [19]. |
| Microtiter Plates (MTP) | 96 / 384 wells [17] | 192 reactions in ~4 days [17]; screen size increased from ~20-30 to ~50-85 per quarter post-automation [18]. | Stereoselective Suzuki–Miyaura couplings, Buchwald–Hartwig aminations, photochemical reactions [17]. |
| UltraHTE (MTP) | 1536 wells [17] | Exploration of larger spaces of reaction parameters [17]. | Optimizing chemistry-related processes, initially from biological assays [17]. |
| ML-Driven Workflow (e.g., Minerva) | 96 wells per batch [6] | Identified optimal conditions in 4 weeks vs. 6-month traditional campaign [6]. | Multi-objective optimization (e.g., yield, selectivity) for challenging transformations like Ni-catalysed Suzuki reaction [6]. |
Table 2: Machine Learning Performance in Navigating Categorical Variables. This table summarizes the performance of different ML acquisition functions used in HTE for optimizing reactions with multiple, competing objectives [6].
| Machine Learning Acquisition Function | Key Feature / Scalability | Performance in Multi-Objective Optimization |
|---|---|---|
| q-NParEgo | Scalable for large batch sizes [6]. | Effective in optimizing multiple competing objectives (e.g., yield and selectivity) [6]. |
| Thompson Sampling with HVI (TS-HVI) | Scalable for large batch sizes [6]. | Effective in optimizing multiple competing objectives (e.g., yield and selectivity) [6]. |
| q-Noisy Expected Hypervolume Improvement (q-NEHVI) | Scalable for large batch sizes [6]. | Effective in optimizing multiple competing objectives (e.g., yield and selectivity) [6]. |
| Sobol Sampling | Used for initial batch selection [6]. | Maximizes initial reaction space coverage to discover informative regions [6]. |
Experimental Protocols
Protocol 1: ML-Driven Multi-Objective Reaction Optimization in a 96-Well HTE Batch Plate
This protocol describes the application of a scalable machine learning framework for optimizing chemical reactions with multiple objectives using an automated HTE batch platform [6].
1. Reaction Setup and Initialization
- Reaction Selection: Select a target chemical transformation (e.g., nickel-catalysed Suzuki coupling [6]).
- Define Search Space: Define the combinatorial space of plausible reaction conditions. This includes categorical variables (e.g., ligands, solvents, additives) and continuous variables (e.g., temperature, concentration). The space should be constrained by practical chemistry knowledge (e.g., excluding unsafe reagent combinations) [6].
- Initial Sampling: Use an algorithmic quasi-random Sobol sampling method to select an initial batch of 96 diverse reaction conditions. This maximizes the initial coverage of the reaction space [6].
2. Automated Reaction Execution
- Liquid Handling: Use an automated liquid handling system to dispense solvents and liquid reagents into a 96-well plate [18].
- Solid Dosing: Employ an automated powder-dosing robot (e.g., CHRONECT XPR) to accurately dispense solid reagents (e.g., catalysts, bases, starting materials) into the designated wells. This ensures precision, especially at sub-milligram scales, and eliminates human error [18].
- Reaction Conditions: Place the sealed 96-well plate on a heating/stirring station that can maintain the required temperature and mixing for all wells simultaneously [17].
3. Analysis and Data Processing
- Product Analysis: After the reaction time has elapsed, analyze the reaction mixtures using inline or offline analytical tools, typically UPLC/MS or GC/MS [17].
- Data Extraction: Quantify reaction outcomes for multiple objectives, such as Area Percent (AP) yield and selectivity [6].
- Data Mapping: Map the collected outcome data to the corresponding experimental conditions in a digital format [6].
4. Machine Learning and Next-Batch Selection
- Model Training: Train a Gaussian Process (GP) regressor on all data collected to date. This model predicts reaction outcomes and their uncertainties for all possible conditions in the defined search space [6].
- Condition Selection: Use a scalable multi-objective acquisition function (e.g., q-NParEgo, TS-HVI) to evaluate all possible conditions. The function balances exploration (trying uncertain conditions) and exploitation (improving on known good conditions) to select the next most informative batch of 96 experiments [6].
- Iteration: Repeat steps 2-4 for as many iterations as desired, typically until convergence or the experimental budget is exhausted [6].
Protocol 2: High-Throughput Catalyst Screening for a Gas-Phase Reaction
This protocol outlines the steps for parallel screening of heterogeneous catalysts using a dedicated 16-reactor HTE batch system [19].
1. System and Catalyst Preparation
- Reactor Loading: Place each unique catalyst to be screened into an individual reactor within the high-throughput system [19].
- System Check: Ensure the modular system is configured for the target application (e.g., gas-phase chemistry, syngas conversion) and is leak-tight [19].
2. Parallelized Reaction and Monitoring
- Process Control: Initiate the flow of reactant gases (e.g., H₂, CO) through all 16 reactors in parallel. The system maintains identical process conditions (pressure, temperature, gas flow rate) across all reactors [19].
- In-line Analytics: Utilize integrated analytical tools to monitor reaction products continuously or at set intervals. This generates high-quality, comparable data for each catalyst [19].
3. Data Evaluation and Scaling
- Performance Analysis: Evaluate catalyst performance based on metrics such as conversion, selectivity, and turnover frequency.
- Scalability Assessment: Use the high-quality data generated by the HTE system to inform decisions on scaling up the most promising catalysts for commercial evaluation [19].
Workflow and Signaling Pathway Visualization
Diagram 1: ML-Driven HTE Optimization Workflow. This diagram illustrates the closed-loop, iterative process of machine-learning-guided high-throughput experimentation.
Diagram 2: Efficient Encoding of Categorical Variables. This diagram shows the transformation of high-cardinality categorical data into a compact numerical format for machine learning.
The Scientist's Toolkit: Essential Research Reagent Solutions
The successful implementation of HTE relies on specialized materials and equipment. The following table details key solutions used in the featured experiments.
Table 3: Key Research Reagent Solutions for HTE Batch Modules.
| Item / Solution | Function in HTE | Application Example |
|---|---|---|
| Automated Powder Dosing System | Precisely dispenses solid reagents (catalysts, starting materials) at milligram to gram scales into reaction vials, ensuring accuracy and reproducibility [18]. | Dosing transition metal complexes and organic starting materials for catalytic cross-coupling reactions in a 96-well plate [18]. |
| Catalyst Libraries | Pre-prepared collections of diverse catalytic complexes (e.g., Ni, Pd) enabling rapid screening for a given transformation [6] [18]. | Screening for optimal catalyst in a Suzuki coupling or Buchwald-Hartwig amination [6] [17]. |
| Diverse Ligand Sets | Collections of ligand structures that, when screened, modulate catalyst activity and selectivity, crucial for reaction optimization [6]. | Identifying the optimal ligand for a nickel-catalysed transformation to improve yield and selectivity [6]. |
| Solvent Kits | A standardized set of solvents covering a range of polarities and properties, allowing for efficient solvent screening [17]. | Included as a categorical variable in an HTE screen to determine the optimal reaction medium [6] [17]. |
| MTP-Compatible Reagent Stocks | Pre-dissolved solutions of common reagents at standardized concentrations, facilitating rapid liquid handling via automated pipetting [17] [18]. | Used in a 96-well plate screen for a photoredox fluorodecarboxylation reaction to test different bases and fluorinating agents [20]. |
Implementing HTE Batch Screening: Protocols and Real-World Applications
High-Throughput Experimentation (HTE) has revolutionized reaction screening in modern chemical and pharmaceutical research. By leveraging automation and miniaturized reaction scales, HTE enables the highly parallel execution of numerous reactions, making the exploration of vast chemical spaces more cost- and time-efficient than traditional one-factor-at-a-time approaches [6]. This application note details a standardized workflow for implementing HTE batch modules, from initial reagent setup to final analysis, framed within the context of accelerating reaction optimization and drug development timelines.
Key Research Reagent Solutions
The success of an HTE campaign hinges on the careful selection and management of reagents. The following table catalogues essential materials and their functions in a typical HTE reaction screening platform [6].
Table 1: Essential Research Reagent Solutions for HTE Screening
| Reagent Category | Example Items | Primary Function in HTE |
|---|---|---|
| Catalysts | Nickel catalysts (e.g., Ni(acac)₂), Palladium catalysts (e.g., Pd₂(dba)₃) | Facilitate key bond-forming reactions (e.g., Suzuki couplings, Buchwald-Hartwig aminations) at low catalyst loadings [6]. |
| Ligands | Diverse phosphine ligands, N-heterocyclic carbenes | Modulate catalyst activity, stability, and selectivity; a primary variable for optimizing challenging transformations [6]. |
| Solvents | Dimethylformamide (DMF), Tetrahydrofuran (THF), 1,4-Dioxane, Toluene | Dissolve reactants and influence reaction outcome, kinetics, and mechanism. Selection is guided by pharmaceutical industry guidelines [6]. |
| Additives | Salts (e.g., K₃PO₄), Bases (e.g., Cs₂CO₃), Acids | Adjust reaction environment (pH, ionic strength), facilitate catalytic cycles, or sequester impurities [6]. |
| Substrates | Aryl halides, Boronic acids, Amines | The core reactants undergoing the chemical transformation of interest; often varied to study substrate scope [6]. |
Standardized HTE Workflow Protocol
This protocol outlines a robust, end-to-end process for conducting reaction screening using HTE batch modules, incorporating machine learning for efficient optimization.
Phase 1: Pre-Experimental Planning & Reagent Setup
Objective: To define the reaction condition space and prepare reagent stocks for highly parallel experimentation.
Methodology:
- Define the Search Space: Compile a discrete combinatorial set of all plausible reaction conditions. This includes categorical variables (e.g., solvents, ligands, additives) and continuous variables (e.g., temperature, concentration) [6].
- Apply Chemical Filters: Programmatically filter out impractical or unsafe condition combinations (e.g., reaction temperatures exceeding solvent boiling points, incompatible reagent pairs like NaH and DMSO) [6].
- Reagent Stock Solution Preparation:
- Prepare concentrated stock solutions of all catalysts, ligands, and substrates in appropriate, degassed solvents.
- Utilize automated liquid handling systems to dispense these stocks into designated wells of a master reaction block (e.g., 96-well format) to ensure precision and reproducibility.
- Store the master block under an inert atmosphere if moisture- or oxygen-sensitive reagents are involved.
Phase 2: Reaction Execution & Parallel Workup
Objective: To initiate reactions in a highly parallel manner and process them for analysis.
Methodology:
- Initial Batch Selection: Initiate the campaign using algorithmic quasi-random Sobol sampling to select an initial batch of experiments (e.g., 1x 96-well plate). This ensures diverse coverage of the reaction condition space [6].
- Reaction Initiation: Use an automated robotic platform to dispense the final reactants or initiating agents (e.g., bases) into the master reaction block. Securely seal the plate to prevent evaporation.
- Environmental Control: Place the reaction block into a pre-heated/cooled agitator (e.g., an orbital shaker within an incubator) to maintain constant temperature and mixing for the specified reaction duration.
- Parallel Quenching & Workup: After the allotted time, automatically transfer the reaction mixtures to a workup block containing a quenching solution (e.g., aqueous buffer, silica slurry). Subsequent parallel operations may include liquid-liquid extraction using an automated plate washer or filtration.
Phase 3: Analysis & Data-Driven Optimization
Objective: To analyze reaction outcomes and use machine learning to guide subsequent experimental batches.
Methodology:
- High-Throughput Analysis: Analyze the worked-up reaction samples using parallel analytical techniques, typically UPLC-MS or HPLC-MS. Key quantitative outputs include Area Percent (AP) Yield and Selectivity [6].
- Machine Learning Model Training: Input the experimental conditions and their corresponding outcomes (yield, selectivity) into a Gaussian Process (GP) regressor. The GP model learns to predict reaction outcomes and their uncertainties for all possible condition combinations within the defined search space [6].
- Next-Batch Experiment Selection: Use a multi-objective acquisition function (e.g., q-NParEgo, Thompson Sampling with Hypervolume Improvement) to select the next batch of experiments. This function balances exploration of uncertain regions of the search space with exploitation of known high-performing regions [6].
- Iterative Optimization: Repeat the cycle of experiment execution, analysis, and model-informed batch selection until convergence is achieved, performance stagnates, or the experimental budget is exhausted.
Workflow Visualization
The following diagram illustrates the integrated, iterative process of the standard HTE workflow.
Quantitative Data Presentation
The performance of the HTE workflow is quantified by its efficiency in navigating the reaction condition space. The table below summarizes key metrics and outcomes from a published optimization campaign [6].
Table 2: Performance Metrics from an HTE Optimization Campaign for a Nickel-Catalyzed Suzuki Reaction
| Parameter | Value / Outcome | Context & Significance |
|---|---|---|
| Search Space Size | ~88,000 conditions | Demonstrates the ability to navigate a vast combinatorial space [6]. |
| HTE Platform | 96-well plates | Standardized format for highly parallel experimentation [6]. |
| Key Outcomes (ML-guided) | 76% AP Yield, 92% Selectivity | Successfully identified high-performing conditions for a challenging transformation where traditional methods failed [6]. |
| Comparison (Chemist-designed) | No successful conditions found | Highlights the advantage of the ML-driven workflow over traditional intuition-based screening [6]. |
| Pharmaceutical Case Study Result | >95% AP Yield and Selectivity | Achieved for both a Ni-catalyzed Suzuki coupling and a Pd-catalyzed Buchwald-Hartwig reaction, validating robustness [6]. |
| Timeline Acceleration | 4 weeks vs. 6 months | ML-driven HTE identified improved process conditions at scale significantly faster than a prior development campaign [6]. |
High-throughput experimentation (HTE) has emerged as a powerful strategy for accelerating chemical synthesis and optimization, offering a systematic approach to navigating complex reaction parameter spaces efficiently [21]. This application note details a proven HTE protocol for the optimization of a Buchwald-Hartwig amination, a cornerstone reaction in pharmaceutical development for forming C–N bonds. The methodology is presented within the broader research context of employing HTE batch modules for reaction screening, enabling the rapid acquisition of rich datasets with minimal time and resource investment [21]. This approach is particularly valuable for drug development professionals and process chemists who require robust, scalable, and data-driven methods to expedite development timelines.
Research Reagent Solutions
The successful execution of an HTE campaign hinges on the preparation and organization of key reagents. The table below catalogues essential materials for a typical Buchwald-Hartwig amination screening.
Table 1: Essential Research Reagents and Materials for HTE Screening
| Reagent/Material | Function/Role in Screening |
|---|---|
| 96-Well Aluminum Reaction Plate | Machined aluminum plate serving as a modular batch reactor for parallel execution of 96 reactions with simultaneous heating and mixing [21]. |
| Solid Transfer Scoops | Enables rapid and parallel transfer of solid reagents, such as catalysts, bases, and ligands, crucial for maintaining high-throughput workflows without robotic automation [21]. |
| Palladium Catalysts | Transition metal catalyst facilitating the cross-coupling reaction. Multiple precursors (e.g., Pd(2)(dba)(3), Pd(OAc)(_2)) are typically screened [21]. |
| Ligand Library | A diverse collection of phosphine-based ligands (e.g., BippyPhos, XPhos, BrettPhos) that modulate the catalyst's reactivity and selectivity [21] [6]. |
| Base Library | Inorganic and organic bases (e.g., K(3)PO(4), Cs(2)CO(3), NaO(^t)Bu) that facilitate the catalytic cycle by deprotonating the amine coupling partner [21]. |
| Solvent Library | A range of organic solvents (e.g., toluene, 1,4-dioxane, DMF) with varying polarity and coordinating ability to solvate reagents and influence reaction outcome [21]. |
| Plastic Filter Plate | Used for parallel post-reaction workup, such as quenching and filtration, to prepare samples for analysis [21]. |
Experimental Protocol & Workflow
This section provides a detailed, step-by-step methodology for conducting an HTE campaign for a Buchwald-Hartwig amination, from initial setup to data analysis.
Protocol for HTE Screening in Multiwell Plates
Objective: To identify optimal reaction conditions for a Buchwald-Hartwig amination by simultaneously screening 96 different combinations of catalyst, ligand, base, and solvent.
Materials and Equipment:
- 96-well aluminum reaction plate
- Magnetic stir bars (one per well)
- Magnetic stirrer
- Solid transfer scoops and pipettes
- Reagents: Aryl halide, amine, palladium catalyst library, ligand library, base library, solvent library
- Plastic filter plate for parallel workup
- Gas Chromatograph (GC) or GC-Mass Spectrometry (GC-MS) for analysis
Procedure:
- Plate Design & Layout: Define a screening array that systematically varies key parameters. A sample design is shown in Table 2.
- Reagent Dispensing: a. Using pipettes, distribute stock solutions of the aryl halide and amine to all 96 wells according to the predetermined layout. b. Using solid transfer scoops, add the appropriate solid catalysts, ligands, and bases to each well [21]. c. Finally, add the designated solvents to each well using pipettes.
- Reaction Execution: Seal the reaction plate and place it on a pre-heated magnetic stirrer/hotplate. Stir the reactions simultaneously for the designated time (e.g., 18 hours) at a constant temperature (e.g., 80-100 °C) [21].
- Parallel Workup and Quenching: After the reaction time, remove the plate from heat and simultaneously quench all reactions by adding a standard quenching solution (e.g., a mixture of water and an organic solvent) across the plate. A filter plate can be used to remove particulates.
- Sample Analysis: Dilute an aliquot from each well and analyze by GC or GC-MS to determine reaction yield and conversion [21].
- Data Analysis: Compile the yields from all 96 experiments to create a comprehensive data matrix. The best-performing condition can be selected for immediate scale-up, or the dataset can be used to inform subsequent, more focused optimization rounds or machine learning-driven campaigns [21] [6].
Quantitative Data from HTE Campaigns
The power of HTE lies in generating large, comparable datasets. The following table summarizes hypothetical quantitative outcomes from a 96-well screening, illustrating how optimal conditions are identified.
Table 2: Exemplary HTE Screening Results for Buchwald-Hartwig Amination (Isolated Yields %)
| Well | Catalyst | Ligand | Base | Solvent | Yield (%) |
|---|---|---|---|---|---|
| A1 | Pd(2)(dba)(3) | XPhos | K(3)PO(4) | Toluene | 85 |
| A2 | Pd(2)(dba)(3) | BrettPhos | Cs(2)CO(3) | 1,4-Dioxane | 92 |
| A3 | Pd(OAc)(_2) | BippyPhos | NaO(^t)Bu | DMF | 45 |
| ... | ... | ... | ... | ... | ... |
| H12 | Pd(OAc)(_2) | JohnPhos | K(3)PO(4) | Toluene | 78 |
Recent studies highlight the synergy between HTE and machine learning (ML). For instance, a scalable ML framework (Minerva) was applied to optimize a Pd-catalysed Buchwald-Hartwig reaction for an Active Pharmaceutical Ingredient (API), identifying multiple conditions achieving >95% yield and selectivity, thereby significantly accelerating process development [6]. Furthermore, data-driven analysis of large historical HTE datasets using statistical methods like z-scores can reveal optimal conditions that differ from traditional literature-based guidelines, providing higher-quality starting points for optimization campaigns [22].
Workflow and Data Analysis Visualization
The overall process of an ML-enhanced HTE campaign, from initial setup to the identification of optimized conditions, can be visualized as a logical workflow. The following diagram delineates the key stages and decision points.
The physical organization of reagents within a 96-well plate is a critical aspect of HTE campaign design. The following diagram illustrates a simplified plate map for a two-dimensional screen.
The precise formation of carbon-carbon (C–C) bonds is a cornerstone of organic synthesis, pivotal for constructing complex molecules in pharmaceuticals, materials science, and agrochemicals [23]. Among the most powerful methods for achieving this are cross-coupling reactions, which have been recognized as significant milestones in organic and organometallic chemistry [23]. The Suzuki-Miyaura cross-coupling (SMC) reaction, in particular, has become an indispensable tool due to its exceptional versatility, mild reaction conditions, and broad functional group tolerance [23] [24]. Its profound impact was underscored by the awarding of the Nobel Prize in 2010 for pioneering work in palladium-catalyzed cross-couplings.
More recently, photoredox catalysis has emerged as a complementary and sustainable strategy for activating small molecules [25]. This approach utilizes light to generate highly reactive species from photocatalysts, enabling unique transformations that are often challenging via traditional thermal pathways. The fusion of photoredox chemistry with established methods like SMC is expanding the synthetic toolbox, allowing chemists to tackle increasingly complex synthetic challenges.
This article details practical applications and protocols for these reactions, framed within the context of High-Throughput Experimentation (HTE) batch modules for reaction screening. The provided guidelines are designed for researchers and development scientists seeking to implement these powerful methods in drug discovery and development programs.
Application Notes & Experimental Protocols
Suzuki-Miyaura Cross-Coupling (SMC)
- Reaction Setup: Conduct all manipulations under an inert atmosphere (N₂ or Ar) using standard Schlenk techniques or in a glovebox.
- Reagents:
- Aryl halide (e.g., 4-bromotoluene) (1.0 equiv, 0.5 mmol)
- Arylboronic acid (e.g., phenylboronic acid) (1.2 equiv, 0.6 mmol)
- Palladium catalyst (e.g., Pd(PPh₃)₄ or Pd(dppf)Cl₂) (2 mol%)
- Base (e.g., K₂CO₃ or Cs₂CO₃) (2.0 equiv, 1.0 mmol)
- Solvent: 5 mL of a 4:1 mixture of Toluene/Ethanol or Dioxane/Water.
- Procedure:
- Charge a dried HTE vial with a magnetic stir bar.
- Weigh in the palladium catalyst, followed by the aryl halide, boronic acid, and base.
- Add the degassed solvent mixture via syringe.
- Seal the vial and heat the reaction mixture to 80-90 °C with stirring for 12-16 hours.
- Monitor reaction progress by TLC or LC/MS.
- Upon completion, cool the reaction to room temperature.
- Quench by adding 10 mL of saturated aqueous NH₄Cl solution and extract with ethyl acetate (3 × 15 mL).
- Dry the combined organic layers over anhydrous MgSO₄, filter, and concentrate under reduced pressure.
- Purify the crude product by flash column chromatography on silica gel.
HTE Considerations for SMC Optimization
The performance of SMC reactions is highly sensitive to several parameters, making them ideal for HTE screening [24]. Key variables to screen in a batch module include:
- Ligands: Test a library of phosphine (monodentate vs. bidentate) and N-heterocyclic carbene (NHC) ligands. Electron-deficient monophosphines often accelerate the transmetalation step [24].
- Boron Source: Evaluate different organoboron reagents (boronic acids, esters, trifluoroborates) to balance reactivity and stability. Neopentyl glycol esters offer a good compromise [24].
- Base and Solvent: Screen bases (e.g., K₃PO₄, KOtBu, TMSO-K) and solvent systems (aqueous/organic mixtures, 2-MeTHF) to mitigate issues like halide inhibition and poor boronate solubility [24].
Photoredox Catalysis
- Reaction Setup: Perform in a dried HTE vial equipped with a magnetic stir bar. Use a transparent vial or reactor suitable for irradiation with visible light.
- Reagents:
- Substrate (e.g., tetrahydrofuran) (1.0 equiv, 0.2 mmol)
- Electrophile (e.g., bromomalonate) (2.0 equiv, 0.4 mmol)
- Photocatalyst (e.g., Eosin Y) (2 mol%)
- Hydrogen atom transfer (HAT) catalyst (e.g., thiol) (optional, 20 mol%)
- Procedure:
- Prepare the substrate and electrophile in the HTE vial.
- Add the photocatalyst and any additives.
- Add Degassed Acetonitrile (2 mL) as solvent.
- Seal the vial and place it in the HTE photoreactor module.
- Irradiate the reaction mixture with ~450-465 nm Blue LEDs while stirring vigorously for 6-24 hours. Ensure the light source is calibrated for consistent photon flux across all wells.
- Monitor the reaction by LC/MS.
- Upon completion, remove the vial from the reactor and concentrate the mixture directly under reduced pressure.
- Purify the residue by flash chromatography.
HTE Considerations for Photoredox Screening
- Light Source: Uniform irradiation across all wells in a batch module is critical. LED arrays provide consistent intensity and wavelength control.
- Photocatalyst Library: Screen a range of organic dyes (Eosin Y, methylene blue, Rose Bengal) and transition-metal complexes ([Ir(ppy)₃], [Ru(bpy)₃]²⁺) to match redox potentials with substrate requirements [25].
- Oxygen Sensitivity: Despite some organic dyes' relative stability, most photoredox cycles involve radical intermediates. Thorough degassing of solvents and reagents is essential for reproducible results in HTE.
Table 1: Comparison of Common Photoredox Catalysts [25]
| Catalyst | λmax (nm) | Excited State | E*red (V vs SCE) | E*ox (V vs SCE) |
|---|---|---|---|---|
| Eosin Y | 520 | Triplet | +0.83 | -1.15 |
| Methylene Blue | 650 | Triplet | +1.14 | -0.33 |
| Rose Bengal | 549 | Triplet | +0.81 | -0.96 |
| Mes-Acr⁺ | 425 | Singlet | +2.32 | - |
Table 2: Key Reaction Parameters for Suzuki-Miyaura Coupling Optimization [23] [24]
| Parameter | Options for HTE Screening | Impact / Consideration |
|---|---|---|
| Electrophile (R-X) | Aryl/Benzyl Chlorides, Bromides, Iodides, Triflates | I > OTf > Br >> Cl (reactivity); Cost & availability |
| Boron Source | Boronic Acids, Pinacol Esters, Neopentyl Glycol Esters, Trifluoroborates | Trade-off between reactivity and stability (protodeboronation) |
| Ligand | P(t-Bu)₃, SPhos, XPhos, dppf, NHC ligands | Dictates stability of Pd(0) and rate of oxidative addition/transmetalation |
| Base | K₂CO₃, Cs₂CO₃, K₃PO₄, KOtBu, TMSOK | Activates boron reagent; Affects solubility of boronate complex |
| Solvent | Toluene/Water, Dioxane/Water, DMF, 2-MeTHF/Water | Polarity affects boronate formation and halide salt inhibition |
Table 3: The Scientist's Toolkit: Key Research Reagent Solutions
| Reagent / Material | Function / Explanation |
|---|---|
| Palladium Precursors (e.g., Pd(OAc)₂, Pd₂(dba)₃) | Source of Pd(0) active species for the catalytic cycle [23]. |
| Buchwald-type Ligands (e.g., SPhos, XPhos) | Bulky, electron-rich phosphines that facilitate oxidative addition of aryl chlorides and stabilize the Pd center [23] [24]. |
| Organoboron Reagents (e.g., Aryl Boronic Esters) | Air- and moisture-stable, less prone to protodeboronation compared to boronic acids, ideal for HTE stock solutions [24]. |
| Organic Photoredox Catalysts (e.g., Eosin Y, Mes-Acr⁺) | Non-toxic, metal-free catalysts that absorb visible light to generate potent oxidants/reductants [25]. |
| Inorganic Bases (e.g., Cs₂CO₃, K₃PO₄) | Weak bases that activate the organoboron reagent for transmetalation while minimizing base-sensitive side reactions [23]. |
| Anhydrous, Degassed Solvents | Essential for both Pd-catalyzed (prevents catalyst oxidation) and photoredox (prevents radical quenching by O₂) reactions. |
Workflow and Mechanism Visualization
Diagram 1: HTE Batch Module Screening Workflow (76 characters)
Diagram 2: Suzuki-Miyaura Catalytic Cycle (72 characters)
Diagram 3: General Photoredox Catalytic Cycle (77 characters)
Application Note: Automated Reaction Screening and Optimization at Eli Lilly
Eli Lilly has pioneered the industrial deployment of custom High-Throughput Experimentation (HTE) platforms to accelerate drug discovery and development processes. The company's approach integrates advanced laboratory automation with machine learning algorithms to synchronously optimize multiple reaction variables, enabling rapid exploration of high-dimensional parametric spaces that were previously impractical to investigate through manual methods [26]. This paradigm shift from traditional one-variable-at-a-time optimization to multivariate synchronous optimization represents a fundamental transformation in pharmaceutical reaction screening, significantly reducing experimentation time while minimizing human intervention.
Lilly's HTE infrastructure encompasses multiple specialized platforms, including a remote-controlled robotic cloud lab in collaboration with Strateos, Inc., and the recently launched Lilly TuneLab AI platform [27] [28]. These systems physically and virtually integrate various aspects of the drug discovery process—including design, synthesis, purification, analysis, sample management, and hypothesis testing—into fully automated workflows. The 11,500 square foot Strateos-powered lab facility operates via a web-based interface that allows research scientists to remotely control experiments with high reproducibility [27].
Quantitative Platform Specifications and Performance Metrics
Table 1: Performance Metrics of Lilly's HTE and AI Platforms
| Platform Component | Key Specifications | Throughput Capacity | Automation Level | Data Integration |
|---|---|---|---|---|
| Strateos Cloud Lab | 11,500 sq ft facility; Integrated synthesis, purification, analysis | Not specified | Full remote operation via web interface | Real-time experiment refinement |
| Lilly TuneLab AI | Trained on $1B+ research investment; Federated learning architecture | Hundreds of thousands of unique molecules | Predictive model deployment | Privacy-preserving data contribution |
| NVIDIA Supercomputer | 1,000+ Blackwell Ultra GPUs; Unified high-speed network | Millions of experiments | AI model training at scale | December 2025 operational date |
Experimental Results and Validation
Lilly's integrated HTE approach has demonstrated significant improvements in reaction optimization efficiency. The machine learning algorithms driving these platforms can identify optimal chemical reaction conditions from complex multivariate parameter spaces that traditionally required extensive manual experimentation [26]. The AI models powering Lilly TuneLab are trained on comprehensive drug disposition, safety, and preclinical datasets representing experimental data from hundreds of thousands of unique molecules, providing unprecedented predictive capability for reaction outcome optimization [28].
The supercomputer infrastructure being developed in partnership with NVIDIA, scheduled to become operational in January 2026, represents the pharmaceutical industry's most powerful computational resource dedicated to drug discovery [29]. This "AI factory" will enable scientists to train AI models on millions of experiments to test potential medicines, dramatically expanding the scope and sophistication of reaction screening and optimization. Eli Lilly anticipates that the full benefits of these advanced HTE capabilities will yield significant returns by 2030, potentially discovering new molecules that would be impossible to identify through human effort alone [29].
Protocol: Implementation of Automated Reaction Screening
Experimental Workflow for HTE Reaction Optimization
The following diagram illustrates the integrated workflow combining robotic automation with AI-driven experimental design and optimization.
Step-by-Step Experimental Procedure
Pre-Experimental Setup Phase
- Reaction Objective Definition: Clearly define the chemical transformation target, desired yield thresholds, and critical quality attributes for the reaction products.
- Parameter Space Identification: Identify all variables to be optimized, including catalyst loading, temperature, solvent systems, concentration, and reaction time.
- Experimental Design Configuration: Using Lilly TuneLab AI platform, configure the design of experiments (DoE) to maximize information gain while minimizing the number of required experiments [28].
Automated Execution Phase
- Reagent Preparation: Utilize the Strateos robotic platform for automated liquid handling, weighing, and dissolution of reaction components in the designated solvent systems [27].
- Reaction Assembly: Implement automated distribution of reaction mixtures into appropriate reaction vessels under controlled atmosphere conditions when necessary.
- Reaction Initiation and Monitoring: Programmable temperature control and stirring initiation across all reaction vessels simultaneously, with real-time monitoring of reaction progress where applicable.
Workup and Analysis Phase
- Automated Quenching and Workup: Robotic execution of standardized workup procedures including extraction, washing, and phase separation.
- Sample Purification: Integration with automated purification systems including flash chromatography, preparative HPLC, or crystallization platforms.
- Analytical Characterization: High-throughput analysis using integrated UPLC/MS, NMR, or other relevant analytical techniques with automated sample injection.
Data Processing and Machine Learning Optimization
- Feature Extraction: Automated extraction of relevant reaction features including conversion, yield, selectivity, and impurity profiles from analytical data.
- Model Training: Application of machine learning algorithms (including those available through Lilly TuneLab) to identify complex relationships between reaction parameters and outcomes [26] [28].
- Predictive Optimization: Use trained models to predict optimal reaction conditions beyond the initially tested parameter space.
- Iterative Refinement: Continuous improvement of models through federated learning approaches as additional data becomes available from ongoing experiments [28].
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 2: Key Research Reagents and Platform Components in Lilly's HTE Ecosystem
| Component Category | Specific Examples | Function in HTE | Implementation Notes |
|---|---|---|---|
| Automation Hardware | Strateos Robotic Platforms; Liquid handlers; Automated purifiers | Enables unattended execution of complex experimental workflows | Remote operation via web interface; 24/7 operational capability |
| Computational Infrastructure | NVIDIA Blackwell Ultra GPUs; High-speed networking | Powers AI/ML model training and complex simulation | 1,000+ GPUs; Enables training on millions of experiments |
| AI/ML Platforms | Lilly TuneLab; Custom optimization algorithms | Predicts optimal reaction conditions; Identifies complex parameter interactions | Federated learning preserves data privacy; Trained on $1B+ research data |
| Data Management Systems | Centralized data repositories; JUMP Cell Painting database | Stores and organizes experimental results for machine learning | Enables batch correction methods like Harmony and Seurat RPCA |
| Analytical Integration | UPLC/MS systems; Automated NMR; HPLC | Provides high-throughput characterization of reaction outcomes | Direct integration with robotic platforms for automated analysis |
Batch Correction and Data Integration Methods
The following diagram illustrates the data processing workflow for managing batch effects in high-throughput screening data, a critical consideration when integrating results across multiple experimental runs.
Implementation of Batch Correction Protocols
Eli Lilly's HTE platforms implement sophisticated batch correction methods to address technical variations across different experimental runs, laboratories, and equipment configurations. Based on benchmarking studies conducted using the JUMP Cell Painting dataset, Harmony and Seurat RPCA have emerged as top-performing methods for reducing batch effects while preserving biological signals [30]. These methods are particularly valuable when integrating data collected across Lilly's distributed research network, including the twelve laboratories that contributed to the JUMP Consortium dataset.
The batch correction workflow begins with identification of batch effects arising from factors such as reagent lots, processing times, equipment calibration, or experimental platforms. Harmony employs an iterative algorithm based on expectation-maximization that alternates between finding clusters with high diversity of batches and computing mixture-based corrections within such clusters [30]. Seurat RPCA operates by identifying pairs of mutual nearest neighbor profiles across batches and correcting for batch effects based on differences between these pairs, making it particularly effective for heterogeneous datasets [30].
Implementation of these batch correction methods enables more accurate integration of HTE data collected across Lilly's distributed research ecosystem, including the Strateos cloud lab, traditional laboratory settings, and partner institutions. This robust data integration capability is essential for building predictive models that generalize across experimental conditions and maximize the value of cumulative research investments exceeding $1 billion [28].
Overcoming HTE Batch Limitations with Advanced Optimization and AI
Within high-throughput experimentation (HTE) batch modules for reaction screening, researchers consistently encounter three pervasive technical challenges: precise temperature control, managing solvent volatility, and the scale-up disconnects that occur when transitioning from microplate screening to gram-scale production [20]. These issues can compromise data integrity, limit the scope of investigable chemistry, and prolong development timelines. The integration of flow chemistry principles and advanced automation presents a robust strategy to mitigate these constraints, enabling more predictive and scalable discovery workflows [20] [6]. This Application Note details specific protocols and solutions to address these challenges, leveraging contemporary technological advancements.
Addressing Temperature Control and Solvent Volatility with Flow Chemistry
In traditional batch-based HTE, precise control over continuous variables like temperature and pressure is challenging, and solvent volatility restricts the use of low-boiling-point solvents at elevated temperatures [20]. Flow chemistry modules overcome these limitations through reactor engineering.
Key Advantages of Flow HTE:
- Enhanced Heat Transfer: The high surface-area-to-volume ratio of microfluidic tubular reactors enables rapid and uniform heat exchange, minimizing hot spots and improving reaction selectivity [20].
- Expanded Process Windows: Flow reactors can be easily pressurized, allowing solvents to be used at temperatures significantly above their atmospheric boiling points. This accelerates reaction rates and provides access to synthetic pathways that are impractical in open-batch vessels [20].
- Closed-System Operation: By containing volatile solvents within a sealed flow path, these systems prevent solvent evaporation and concentration changes, ensuring reaction consistency and maintaining a safe working environment [20].
Experimental Protocol: High-Temperature Reaction in a Volatile Solvent
Aim: To execute a reaction in a volatile solvent (e.g., Diethyl Ether, BP ~35°C) at 100°C.
Materials:
- Reactor System: Commercially available or bespoke flow chemistry system (e.g., Vapourtec Ltd UV150 photoreactor) capable of being pressurized [20].
- Reagent Solutions: Pre-prepared solutions of reactants in the volatile solvent.
- Pumping System: Syringe or piston pumps for precise fluid delivery.
- Back-Pressure Regulator (BPR): To maintain constant pressure within the system.
- Temperature-Controlled Heater/Heat Exchanger.
Procedure:
- System Priming and Pressurization: Fill the reagent solutions into the syringe pumps. Prime the entire flow path, including the reactor and BPR, with the solvent. Set the BPR to a pressure sufficient to maintain the solvent in a liquid state at the target temperature (e.g., >2 bar for diethyl ether at 100°C).
- Temperature and Flow Rate Calibration: Set the reactor block temperature to 100°C. Calculate and set the flow rate of the reagent solutions to achieve the desired residence time. For example, with a reactor volume of 10 mL, a flow rate of 2 mL/min will give a residence time of 5 minutes.
- Reaction Execution: Initiate the flow of reagents. Allow the system to stabilize for at least three residence times before collecting product.
- Product Collection and Monitoring: Collect the output stream into a suitable container. Monitor reaction consistency using inline Process Analytical Technology (PAT) such as FTIR or NMR, if available [20].
Troubleshooting:
- Clogging: If precipitation occurs, consider diluting the reaction stream or introducing a co-solvent.
- Pressure Fluctuations: Check for leaks or obstructions in the flow path. Ensure the BPR is functioning correctly.
Bridging the Scale-Up Disconnect
A significant drawback of well-plate HTE is that optimized conditions often require extensive re-optimization when scaled to production volume due to changes in heat and mass transfer efficiency [20]. Flow chemistry directly addresses this "scale-up disconnect."
Key Advantages for Scale-Up:
- Scale-Out, Not Scale-Up: In flow systems, scale is increased by prolonging the process run-time (numbering-up) or using larger reactors with identical geometries, rather than transferring the process to a larger vessel with different physical characteristics [20]. This maintains consistent heat and mass transfer properties from milligram to kilogram scale [20].
- Process Intensification: Flow systems enable access to more aggressive conditions (high T, P), which can lead to more efficient and cleaner reactions, simplifying downstream processing at all scales [20].
Table 1: Quantitative Comparison of Scale-Up Scenarios
| Scale | Batch/Well-Plates | Flow Chemistry (Scale-Out) |
|---|---|---|
| Screening Scale | ~300 μL in 96-well plates [20] | Microreactors (μL-mL volume) |
| Optimization Scale | Requires re-optimization; different vessel geometry | Continuous process; gram quantities by extended run-time |
| Production Scale | Multi-step transfer to pilot plant; transfer inefficiencies | Direct scale-up using larger reactors of identical geometry; kg/day possible [20] |
| Key Disconnect | Heat/mass transfer changes with vessel size | Consistent heat/mass transfer across scales |
Case Study Protocol: Gram-to-Kilogram Scale-Up of a Photoredox Reaction
This protocol is adapted from the work of Jerkovic et al. on a flavin-catalyzed photoredox fluorodecarboxylation [20].
Aim: To scale up a photochemical reaction from a 2 g to a 1.23 kg scale without re-optimizing core reaction parameters.
Materials:
- Photoreactor: A commercial flow photoreactor (e.g., Vapourtec UV150) or a custom-built equivalent [20].
- Pumping System: High-capacity pumps for continuous operation.
- Feed Solutions: Concentrated solutions of reactants and catalyst in a homogeneous solvent system.
Procedure:
- Initial HTE and Microscale Validation:
- Conduct initial reaction screening in a 96-well plate photoreactor to identify promising catalyst, base, and solvent combinations [20].
- Transfer the top-performing conditions to a small-scale flow reactor (e.g., 2 g scale) to validate performance in a continuous system. Adjust parameters like light power intensity and residence time as needed.
- Intermediate Scale-Up:
- Using a "two-feed" setup where reactant streams are combined immediately before the photoreactor, gradually increase the production rate [20].
- On a 100 g scale, confirm that conversion and yield remain consistent with the small-scale flow process.
- Kilogram-Scale Production:
- Run the optimized process continuously. In the case study, this achieved a throughput of 6.56 kg per day and a final yield of 92% on a 1.23 kg scale, directly from the conditions identified during smaller-scale flow optimization [20].
Critical Parameters for Success:
- Homogeneity: Ensure the reaction mixture is homogeneous to prevent clogging during long-term operation [20].
- Residence Time Distribution: Characterize the reactor to ensure narrow residence time distribution, which is critical for maintaining selectivity at large scale.
The Scientist's Toolkit: Research Reagent Solutions
The following table details key components of an automated HTE platform that integrates flow chemistry to address the discussed challenges.
Table 2: Essential Components for an Advanced HTE-Flow Platform
| Item | Function | Application Note |
|---|---|---|
| Liquid Handling Robot | Automated dispensing of precursor solutions with high precision. | Minimizes human error; essential for preparing reactant mixtures for sol-gel, Pechini, or other wet syntheses in a high-throughput manner [31]. |
| Microwave Solvothermal Reactor | Provides rapid, controlled heating for reactions under pressure. | Enables high-throughput exploration of hydro/solvothermal syntheses, often difficult to automate [31]. |
| Automated Flow Reactor | Continuous, pressurized reaction execution with precise control over residence time and temperature. | Core module for overcoming solvent volatility and temperature control challenges; enables safe use of hazardous reagents [20]. |
| In-line Process Analytical Technology (PAT) | Real-time reaction monitoring (e.g., via FTIR, UV-Vis, NMR). | Provides immediate feedback on conversion and selectivity, closing the loop for autonomous optimization [20] [6]. |
| Back-Pressure Regulator (BPR) | Maintains constant pressure within a flow reactor. | Critical for using volatile solvents at elevated temperatures and for preventing gas formation from disrupting flow profiles. |
Workflow for an Integrated HTE and Machine Learning Optimization Campaign
Modern approaches combine automated HTE with machine learning (ML) to navigate complex reaction spaces efficiently. The following diagram illustrates this closed-loop workflow, which is particularly effective for multi-objective optimization (e.g., maximizing yield and selectivity).
Diagram Title: Closed-loop ML-driven HTE workflow.
Workflow Description:
- Define Reaction Space: A chemist defines a vast combinatorial set of plausible reaction conditions, including categorical (e.g., solvent, ligand) and continuous (e.g., temperature, concentration) variables [6].
- Initial Sampling: An algorithmic method like Sobol sampling selects an initial batch of experiments that are diverse and well-spread across the defined reaction space [6].
- Automated HTE Execution: The selected reactions are carried out automatically on a robotic HTE platform, such as a 96-well system [6].
- High-Throughput Analysis: Reaction outcomes (e.g., yield, selectivity) are rapidly quantified using automated analytical techniques.
- Machine Learning Model Training: The experimental data is used to train a surrogate model (e.g., a Gaussian Process regressor) that predicts reaction outcomes and their uncertainties for all possible conditions in the search space [6].
- Bayesian Optimization: An acquisition function (e.g., q-NParEgo, TS-HVI) uses the model's predictions to balance exploration (testing uncertain conditions) and exploitation (testing conditions predicted to be high-performing). It selects the next most informative batch of experiments to run [6].
- Iteration: The loop (steps 3-6) continues until the optimization objectives are met or the experimental budget is exhausted, efficiently identifying global optima with minimal experiments [6]. This approach has been shown to optimize challenging reactions, such as Ni-catalyzed Suzuki couplings, where traditional HTE plates failed [6].
The Role of Machine Learning and Bayesian Optimization for Efficient Parameter Search
In modern chemical and pharmaceutical research, high-throughput experimentation (HTE) has become an indispensable tool for accelerating reaction discovery and optimization. The core challenge, however, has shifted from merely conducting numerous experiments to intelligently navigating the vast, multi-dimensional parameter spaces these systems can explore. The integration of machine learning (ML), particularly Bayesian optimization (BO), with HTE batch modules represents a paradigm shift, enabling researchers to extract maximum information from minimal experiments. This approach moves beyond traditional one-factor-at-a-time (OFAT) and statistical design of experiments (DoE) methods, which often struggle with complex interactions between variables and the high resource costs of exhaustive screening [26] [32]. By framing the search for optimal reaction conditions as a black-box optimization problem, BO provides a powerful, data-efficient strategy for guiding HTE campaigns. This application note details the principles, protocols, and practical implementation of ML-driven BO within HTE frameworks, providing researchers with a blueprint for accelerating development timelines in reaction screening and drug development.
Theoretical Foundations of Bayesian Optimization
Bayesian Optimization is a sample-efficient, sequential strategy for the global optimization of black-box functions that are expensive to evaluate [33]. This makes it ideally suited for guiding HTE campaigns where each experimental batch consumes significant time and resources. The power of BO stems from its core components, which work in concert to balance the exploration of unknown regions of the parameter space with the exploitation of known promising areas [32].
Probabilistic Surrogate Model: The foundation of BO is a probabilistic model that approximates the unknown objective function (e.g., reaction yield or selectivity). The most common surrogate is the Gaussian Process (GP), which provides a distribution over functions. For any set of input parameters, a GP returns a Gaussian distribution characterized by a mean (the predicted outcome) and a variance (the uncertainty in the prediction) [33] [34]. This uncertainty quantification is crucial for guiding the search. The behavior of the GP is defined by its covariance function, or kernel, which encodes assumptions about the function's smoothness and shape [33].
Acquisition Function: This function leverages the predictions from the surrogate model to decide which set of parameters to test next. It automatically balances exploration (sampling in regions of high uncertainty) and exploitation (sampling in regions with a high predicted mean) [33]. Common acquisition functions include Expected Improvement (EI), Upper Confidence Bound (UCB), and Probability of Improvement (PI). For multi-objective optimization, advanced functions like q-Noisy Expected Hypervolume Improvement (q-NEHVI) are employed [6] [32].
The BO process is inherently iterative. After an initial set of experiments, the surrogate model is updated with the new data, and the acquisition function selects the next batch of experiments. This loop continues until convergence or the exhaustion of the experimental budget [32].
ML-BO Integration in HTE Frameworks: Protocols and Application Notes
The synergy between ML-driven BO and HTE platforms transforms the reaction optimization workflow from a static, human-guided process to a dynamic, adaptive, and autonomous one. The following protocol outlines the standard workflow for implementing this integrated approach.
Protocol: Iterative ML-BO for Reaction Optimization in HTE
Objective: To efficiently identify optimal reaction conditions within a high-dimensional parameter space using a closed-loop HTE system guided by Bayesian optimization.
Workflow Overview: The diagram below illustrates the iterative, closed-loop workflow of a Bayesian Optimization campaign within an HTE framework.
Step-by-Step Procedure:
Problem Definition and Search Space Formulation
- Define Objectives: Clearly specify the primary objectives to be optimized (e.g., yield, selectivity, cost, E-factor). Multiple objectives can be handled simultaneously [6].
- Define Parameters and Constraints: Identify all continuous (e.g., temperature, concentration, time) and categorical (e.g., solvent, catalyst, ligand) variables. Incorporate practical constraints to filter out unsafe or impractical conditions (e.g., temperatures exceeding solvent boiling points) [6].
- Representation: Convert categorical variables into numerical descriptors suitable for the ML model.
Initial Batch Selection
- Employ quasi-random Sobol sampling to select the initial batch of experiments. This method ensures the initial conditions are well-spread and diverse across the entire search space, maximizing the initial information gain [6].
- The batch size (e.g., 24, 48, or 96 reactions) should align with the capacity of the HTE platform [6].
High-Throughput Experimentation and Analysis
- Execute Experiments: Use automated HTE platforms (e.g., liquid handlers, solid dispensers) to perform the planned reactions in parallel.
- Analyze Outcomes: Quantify the reaction outcomes (e.g., via UPLC, GC) for all experiments in the batch. Compile the data into a structured format.
Model Training and Updating
- Train Surrogate Model: Use the accumulated experimental data to train a Gaussian Process (GP) model. The GP will learn the relationship between input parameters and the objective(s).
- Model Output: The GP provides a probabilistic prediction of the objective(s) for any untested condition in the search space, along with an associated uncertainty [6] [34].
Next-Batch Candidate Selection
- Evaluate Acquisition Function: Use an acquisition function (e.g., q-NParEgo, TS-HVI for multi-objective problems) to evaluate all possible conditions in the search space [6]. The function will score conditions based on both high predicted performance (exploitation) and high uncertainty (exploration).
- Select Next Batch: Choose the set of conditions that maximizes the acquisition function for the next round of HTE.
Iteration and Termination
- Repeat steps 3-5 for the desired number of iterations or until a convergence criterion is met (e.g., minimal improvement over several cycles, achievement of a performance threshold, or exhaustion of the experimental budget).
- The final output is a set of Pareto-optimal conditions that represent the best trade-offs between the multiple objectives.
Application Notes and Case Studies
Case Study 1: Optimization of a Nickel-Catalyzed Suzuki Reaction
- Challenge: Traditional chemist-designed HTE plates failed to find successful conditions for a challenging Ni-catalyzed Suzuki coupling [6].
- ML-BO Implementation: The Minerva framework was deployed in a 96-well HTE campaign, exploring a space of 88,000 possible conditions [6].
- Outcome: The BO approach identified conditions achieving 76% area percent (AP) yield and 92% selectivity, successfully navigating a complex landscape with unexpected chemical reactivity where traditional methods failed [6].
Case Study 2: Pharmaceutical Process Development
- Challenge: Accelerate the process development for Active Pharmaceutical Ingredient (API) syntheses.
- ML-BO Implementation: The framework was applied to optimize both a Ni-catalyzed Suzuki coupling and a Pd-catalyzed Buchwald-Hartwig reaction [6].
- Outcome: The BO workflow identified multiple high-performing conditions achieving >95% AP yield and selectivity for both transformations. In one instance, this approach led to the identification of improved process conditions at scale in just 4 weeks, compared to a previous 6-month development campaign [6].
Performance Benchmarking and Quantitative Analysis
The effectiveness of ML-BO is demonstrated through both simulated benchmarks and real-world experimental validations. Key performance metrics include the hypervolume indicator, which measures the quality and diversity of solutions in multi-objective optimization, and the number of experiments required to reach a performance target.
Table 1: Benchmarking Scalable Multi-Objective Acquisition Functions in HTE (Based on In-Silico Studies from [6])
| Acquisition Function | Key Principle | Scalability (Batch Size) | Performance Notes |
|---|---|---|---|
| q-NParEgo | Scalarizes multiple objectives for parallel selection | High (96-well) | Robust performance in large parallel batches and high-dimensional spaces [6]. |
| TS-HVI | Thompson Sampling with Hypervolume Improvement | High (96-well) | Efficiently handles high-dimensional search spaces and reaction noise [6]. |
| q-NEHVI | Direct hypervolume improvement calculation | Lower (Limited scalability with batch size) | Theoretically appealing but can be computationally intensive for very large batches [6]. |
Table 2: Experimental Performance Comparison: Traditional vs. ML-BO Approaches
| Optimization Method | Case Study / Context | Key Outcomes | Experimental Efficiency |
|---|---|---|---|
| Chemist-Designed HTE | Ni-catalyzed Suzuki Reaction [6] | Failed to find successful reaction conditions. | N/A (Unsuccessful) |
| ML-BO (Minerva) | Ni-catalyzed Suzuki Reaction [6] | 76% AP Yield, 92% Selectivity. | Successful optimization in one 96-well campaign [6]. |
| Traditional Development | API Synthesis (Industrial Process) [6] | Successful, but lengthy development. | ~6-month campaign [6]. |
| ML-BO Workflow | API Synthesis (Industrial Process) [6] | >95% AP Yield and Selectivity. | ~4-week campaign [6]. |
| Grid Search | Limonene Production in E. coli [33] | Converged to optimum. | Required 83 investigated points [33]. |
| BO (BioKernel) | Limonene Production in E. coli [33] | Converged to optimum. | Required only 18 points (22% of grid search) [33]. |
The Scientist's Toolkit: Essential Reagents and Materials
Implementing an ML-BO guided HTE campaign requires both physical laboratory tools and computational resources.
Table 3: Key Research Reagent Solutions for ML-BO HTE
| Category | Item | Function in ML-BO HTE |
|---|---|---|
| HTE Hardware | Automated Liquid Handler / Solid Dispenser | Enables highly parallel execution of numerous reactions at miniaturized scales, a prerequisite for data-intensive BO [6]. |
| 24/48/96-well Reaction Blocks | Standardized reaction vessels for parallel experimentation under controlled environments [6]. | |
| Analysis | UPLC / GC / GC-MS | Provides high-throughput, quantitative analysis of reaction outcomes, generating the data points for the BO loop [6]. |
| Computational | Bayesian Optimization Software (e.g., Summit, Minerva, BioKernel) | Provides the algorithms for surrogate modeling (GP) and acquisition function optimization to guide experimental design [6] [33] [32]. |
| Chemical Reagents | Broad Catalyst/Ligand Kits | Essential for exploring categorical variables in reaction optimization spaces (e.g., metal catalysis) [6]. |
| Diverse Solvent Libraries | Allows the algorithm to probe solvent effects, a critical categorical parameter [6]. |
Advanced Concepts and Visualization of Algorithmic Workflow
For complex optimization problems, the standard BO workflow can be extended with advanced ML concepts to enhance performance and applicability. The diagram below illustrates the architecture of a scalable multi-objective BO system designed for large HTE batches.
Key Advanced Concepts:
- Handling Categorical Variables: The optimization of categorical variables (e.g., ligand identity) is a significant strength of modern BO frameworks. These are represented numerically, and the algorithm explores distinct combinations to find promising "islands" of reactivity, which are then refined by adjusting continuous parameters [6].
- Multi-Objective Optimization: Real-world process chemistry often involves competing objectives (e.g., yield vs. cost). BO efficiently maps out the Pareto front—a set of non-dominated solutions representing the optimal trade-offs between all objectives [6] [32]. The hypervolume metric is then used to quantify the performance of the optimization [6].
- Noise and Constraints: Biological and chemical data are inherently noisy. BO frameworks can incorporate noise models (e.g., heteroscedastic noise) to remain robust against experimental variability [33] [35]. Furthermore, known physical or safety constraints can be hard-coded into the search space to prevent the algorithm from suggesting impractical experiments [6].
- Transfer Learning and Multi-Fidelity Modeling: Emerging techniques allow BO to leverage data from related experiments or from cheaper, lower-fidelity simulations (e.g., computational screening) to warm-start the optimization, further reducing the experimental burden [32] [35].
Integrating In-line Analytics and Process Analytical Technology (PAT) for Real-Time Feedback
Within High-Throughput Experimentation (HTE) batch modules for reaction screening, the integration of in-line analytics and Process Analytical Technology (PAT) is transformative. It shifts the paradigm from post-reaction analysis to real-time, data-rich experimentation. This approach provides researchers with immediate feedback on reaction progression, enabling the rapid optimization of chemical synthesis and biopharmaceutical processes. The core value lies in its ability to capture dynamic process data—such as concentration profiles, particle formation, and thermal events—as they occur, without intrusive sampling or process interruption. This application note details practical methodologies and protocols for implementing such systems, framed within the context of advanced reaction screening research.
Key Technologies and Quantitative Specifications
The selection of appropriate PAT tools is governed by the Critical Process Parameters (CPPs) and Critical Quality Attributes (CQAs) relevant to the reaction. The following technologies are central to establishing a real-time feedback loop in HTE batch modules.
The table below summarizes the core in-line analytical techniques and their key specifications for integration into HTE reactors.
Table 1: Key In-line PAT Tools and Their Technical Specifications for HTE Integration
| Analytical Technique | Measured Parameters | Typical Data Density (per experiment) | Key Technical Specifications for HTE | Primary Application in Reaction Screening |
|---|---|---|---|---|
| Raman Spectroscopy [36] | Chemical composition, molecular structure, reaction conversion | 100-1000s of spectra | Non-invasive; no probes/wires in reaction mixture; optional integrated feature | Monitoring reaction pathways and intermediate formation |
| Real-time MALS (RT-MALS) [37] | Absolute molar mass, aggregate formation | Continuous real-time data stream | PAT application; sensitive to aggregates/particles >25-30 nm; direct molecular weight determination [37] | Quantifying protein aggregation, viral capsid assembly, polymer conjugation |
| Dynamic Light Scattering (DLS) [37] | Hydrodynamic radius, particle size distribution, aggregation state | 100s of measurements (via plate reader) | High-throughput (1000s of conditions/day); minimal sample volume (10 μL) [37] | Assessing colloidal stability, protein-protein interactions, and particle formation |
| Non-invasive Temperature Profiling [36] | Internal reactor temperature in real-time | 1000s of data points | Advanced thermopile technology; contactless measurement; feedback control from -10°C to 150°C [36] | Characterizing exothermic/endothermic events and ensuring precise thermal control |
| Transmissivity (Turbidity) & Color Imaging [36] | Cloud points, phase separation, particle size/shape, reaction texture | Continuous imaging & data points | Probe-free; provides visual insight into particle characteristics and mixture homogeneity [36] | Identifying clear/cloud points and monitoring solid formation or oil separation |
Integrated Experimental Protocol for PAT-led Reaction Screening
This protocol describes a consolidated workflow for running a reaction screening campaign with integrated in-line analytics for real-time feedback, suitable for systems like the ReactALL platform [36].
Protocol: Automated Reaction Screening with Real-Time Feedback
Objective: To screen multiple reaction conditions in parallel while collecting real-time data on conversion, particle formation, and thermal events to enable immediate process understanding and optimization.
Materials and Reagents:
- HTE Batch Module: e.g., ReactALL system with five parallel reactors [36].
- PAT Suite: Integrated Raman spectrometer, transmissivity sensors, color cameras, and non-invasive temperature sensors [36].
- Automated Sampling System: e.g., SmartCap technology for automated sampling, quenching, and dilution into HPLC vials [36].
- Reagents: Reaction substrates, catalysts, solvents, and quenching agents.
- Analytical Standards: For HPLC/UPLC calibration relevant to the reaction system.
Methodology:
Step 1: Experimental Design & System Setup
- Design of Experiments (DoE): Define the reaction variable space (e.g., temperature, stoichiometry, catalyst, solvent) and program the sequence into the HTE module's software.
- Reactor Initialization: Charge each of the five reactors with a minimal working volume (e.g., 5-10 mL) of the reaction mixture according to the DoE [36].
- PAT & Dosing Calibration: Power on and calibrate all in-line analytical probes (Raman, turbidity) and the automated liquid dosing module (e.g., DoseALL) [36]. Verify temperature calibration in each reactor.
Step 2: Process Initiation & Data Acquisition
- Start Reaction: Initiate the reaction sequence. The system begins overhead stirring with specialized agitators to suspend solids without grinding [36].
- Activate Real-Time Monitoring: Simultaneously launch data acquisition from all PAT tools:
- Raman: Begin continuous collection of spectra to monitor reactant decay and product formation.
- Temperature & Turbidity: Start logging real-time temperature profiles and transmissivity data to track thermal events and phase changes [36].
- Imaging: Initiate periodic image capture to visually monitor particle formation and mixture homogeneity [36].
Step 3: Automated Sampling & Analysis
- Trigger Sampling: At pre-defined time intervals, the system automatically executes the SmartCap sequence: Sample -> Quench -> Dilute -> Rinse -> Transfer to HPLC vial [36].
- Off-line Correlation: Analyze the quenched samples via HPLC/UPLC. Use this data to validate and calibrate the in-line Raman spectroscopy models for quantitative analysis.
Step 4: Data Integration & Real-Time Decision Making
- Data Fusion: The platform software (designed for the "Lab of the Future") correlates all data streams—in-line (Raman, temperature, turbidity) and off-line (HPLC)—into a unified data set [36].
- Process Intervention: Based on real-time data, the system or scientist can make informed decisions. For example, if an exotherm is detected via temperature profiling [36] or an unwanted precipitate is observed via imaging [36], a feedback loop can adjust the jacket temperature or trigger an early termination.
The following diagram illustrates the complete integrated workflow and data feedback loop:
Diagram 1: PAT-led reaction screening workflow with a real-time feedback loop.
The Scientist's Toolkit: Essential Research Reagent Solutions
The successful implementation of PAT requires not only hardware but also an understanding of the key materials and reagents that define the system under test.
Table 2: Essential Reagents and Materials for PAT-based Reaction Screening
| Item/Category | Function in the Experiment | Example Use-Case in Protocol |
|---|---|---|
| High-Throughput DLS Plate Reader [37] | Rapidly assesses protein-protein interactions, colloidal stability, and aggregation propensity across thousands of conditions. | Screening buffer and excipient conditions for a biotherapeutic formulation to identify compositions that minimize aggregation [37]. |
| SEC-MALS (Size-Exclusion Chromatography with MALS) [37] | Provides absolute molar mass and size for soluble aggregates and conjugates, independent of column retention. | Characterizing the soluble aggregate profile of a monoclonal antibody or determining the Drug-Antibody Ratio (DAR) of an ADC post-reaction [37]. |
| CG-MALS (Composition-Gradient MALS) [37] | Determines affinity, stoichiometry, and weak interactions (including at high concentration) in solution without labels. | Studying the binding affinity of a drug candidate to its target protein or quantifying reversible self-association in high-concentration protein formulations [37]. |
| Automated Sampling & Quenching Fluids [36] | Enables representative, quantitative sample removal and reaction arrest for correlative off-line analysis. | A pre-programmed sequence uses a quench solvent to instantly stop a reaction at precise timepoints for HPLC analysis, providing ground-truth data for in-line models [36]. |
| Stability-Inducing Excipients | Stabilize proteins and other molecules against aggregation, surface adsorption, and chemical degradation. | Included in the DoE to find optimal conditions for long-term storage of a biologic, using DLS and SEC-MALS as key stability indicators [37]. |
The integration of in-line analytics and PAT within HTE batch modules represents the forefront of reaction screening research. It moves the discipline beyond simple "make-and-test" cycles into a realm of deep, real-time process understanding. By implementing the technologies and protocols outlined here—such as non-invasive spectroscopy, real-time light scattering, and automated sampling—research scientists can acquire rich, kinetic datasets that dramatically accelerate development timelines. This approach not only optimizes for yield and purity but also builds fundamental process knowledge, ensuring robust and scalable manufacturing processes for the pharmaceuticals of tomorrow.
From Brute-Force Screening to Smart, Resource-Efficient Autonomous Workflows
The discovery and optimization of chemical reactions are fundamental to advancing synthetic chemistry, materials science, and pharmaceutical development. Traditional approaches often rely on iterative, one-factor-at-a-time (OFAT) experimentation guided by chemical intuition, which can be both time-consuming and resource-intensive. High-Throughput Experimentation (HTE) has emerged as a powerful alternative, enabling the parallel execution of numerous reactions in miniaturized formats to rapidly explore vast chemical spaces. However, initial HTE implementations often employed "brute-force" screening—testing extensive predefined condition grids—which, while an improvement over OFAT, remains inefficient for navigating high-dimensional parameter spaces.
A paradigm shift is now underway, moving from these brute-force methods toward intelligent, autonomous workflows that leverage machine learning (ML) and advanced automation. This evolution is driven by the need for greater resource efficiency and the ability to tackle more complex optimization challenges. These smart systems can prioritize experiments based on predicted outcomes, dramatically reducing the number of reactions required to identify optimal conditions. This Application Note details protocols and methodologies for implementing these advanced workflows, with a specific focus on HTE batch modules for reaction screening research.
The Evolution of HTE Screening Methodologies
Traditional Brute-Force Screening
Traditional brute-force HTE relies on pre-designed experimental arrays, often in 96- or 384-well plate formats, to screen a fixed set of conditions. This approach is characterized by its comprehensive nature, exploring a wide but predefined matrix of parameters such as catalysts, solvents, and ligands. A common strategy involves designing fractional factorial screening plates with grid-like structures that distill chemical intuition into a physical plate design [6]. While effective for initial condition mapping, this method explores only a limited subset of fixed combinations and can miss optimal regions in complex chemical landscapes. Its major limitation is the combinatorial explosion of possible experiments when multiple parameters are investigated simultaneously, making exhaustive screening intractable even with parallelization [6].
The Shift to Smart, ML-Driven Workflows
Modern smart workflows integrate HTE with machine learning algorithms to create closed-loop, autonomous optimization systems. These systems use data-driven approaches to guide experimental design, moving beyond fixed grids to adaptive exploration. The core advantage lies in their ability to balance exploration (investigating uncertain regions of parameter space) with exploitation (refining known promising conditions), a capability embodied by Bayesian optimization frameworks [6].
Key advantages of smart workflows include:
- Resource Efficiency: Dramatically reduced experimental burden compared to brute-force screening
- Handling of Complexity: Effective navigation of high-dimensional search spaces with categorical and continuous parameters
- Multi-Objective Optimization: Simultaneous optimization of multiple objectives (e.g., yield, selectivity, cost)
- Accelerated Discovery: Identification of high-performing conditions in fewer experimental iterations
Table 1: Comparison of Screening Methodologies
| Feature | Brute-Force Screening | Smart Autonomous Workflows |
|---|---|---|
| Experimental Design | Fixed, pre-defined grids | Adaptive, data-driven selection |
| Parameter Space Exploration | Limited subset of combinations | Comprehensive navigation of high-dimensional spaces |
| Resource Efficiency | Lower (high experimental burden) | Higher (focused experimentation) |
| Optimization Capability | Single-objective focus | Native multi-objective optimization |
| Chemical Intuition | Primarily upfront design | Continuous integration of domain knowledge |
| Typical Batch Size | 24-96 reactions per plate [38] [6] | 24-96 reactions per iteration [6] |
| Automation Level | Semi-automated setup and analysis | Fully closed-loop autonomous systems |
Essential Components of an Autonomous HTE Workflow
Implementing a smart, resource-efficient HTE workflow requires the integration of several key components: automated reaction handling, advanced analytical techniques for quantification, and sophisticated data processing capabilities.
Automated Reaction Setup and Execution
Modern HTE systems leverage programmable liquid handlers and automated platforms for reproducible reaction setup and execution. For example, standardized and traceable protocols can be developed utilizing an OT-2 liquid handler, where stock solutions of substrates, reagents, and catalysts are loaded onto the deck and transferred into 96-position reaction blocks using custom protocols defined via an open-source Python API [38]. This approach enables careful optimization of protocols to minimize dead volumes and allows integration of custom laboratory equipment such as reaction blocks and vial holders. Post-reaction, the liquid handler can automatically sample each well, filter, dilute, and transfer samples to analysis vials, ensuring consistent workup and minimizing human error [38].
Calibration-Free Quantification Techniques
A significant bottleneck in traditional HTE has been the need for isolated product references for calibration. Recent advances enable calibration-free quantification through innovative analytical approaches:
- GC-Polyarc-FID System: This technology converts organic compounds to methane with >99.9% efficiency prior to detection by Flame Ionization Detection (FID), ensuring a uniform detector response dependent only on a compound's number of carbon atoms. This enables accurate quantification without individual product calibration, except for samples in sulfur-containing solvents or fully fluorinated analytes [38].
- Retention Index Mapping: Mapping between peaks in GC-MS and GC-Polyarc-FID chromatograms is performed by assigning all peaks Kováts retention indices (RIs), requiring only two additional calibration measurements with commercially available alkane standards [38].
This combination allows parallel identification (via GC-MS) and robust quantification (via GC-Polyarc-FID) of diverse reaction products without the need for individual reference materials.
Automated Data Processing with Open-Source Tools
The data generated by HTE workflows requires specialized processing tools. The pyGecko open-source Python library provides comprehensive analysis tools for processing GC raw data, allowing determination of reaction outcomes for a 96-reaction array in under a minute [38]. Key features include:
- Parsing capabilities for proprietary vendor formats via the msConvert tool from ProteoWizard
- Automated peak detection, integration, and background subtraction
- Retention index calculation and peak matching between MS and FID data
- Visualization tools and export compatibility with the Open Reaction Database (ORD) schema [38]
Table 2: Research Reagent Solutions for Autonomous HTE
| Component | Function | Example Implementation |
|---|---|---|
| Liquid Handler | Automated reagent transfer and reaction setup | OT-2 liquid handler with custom Python protocols [38] |
| Analysis System | Product identification and quantification | Parallel GC-MS and GC-Polyarc-FID analysis [38] |
| Data Processing | Automated raw data interpretation | pyGecko Python library for GC data processing [38] |
| ML Optimization | Experimental design and outcome prediction | Minerva framework for Bayesian optimization [6] |
| Reaction Platform | Miniaturized parallel reaction execution | 96-well reaction blocks with temperature control [38] |
Protocol: Implementing an ML-Driven Optimization Campaign
This protocol outlines the steps for implementing a machine learning-guided reaction optimization campaign using Bayesian optimization, suitable for both academic and industrial research settings.
Experimental Design and Initialization
Step 1: Define Reaction Condition Space
- Enumerate all plausible reaction conditions including catalysts, ligands, solvents, bases, and temperature ranges
- Convert categorical variables (e.g., molecular structures) into numerical descriptors using appropriate representations
- Apply chemical knowledge filters to exclude impractical conditions (e.g., temperatures exceeding solvent boiling points, unsafe reagent combinations) [6]
Step 2: Initial Experimental Batch Selection
- Employ algorithmic quasi-random Sobol sampling to select initial experiments
- Aim for diverse coverage of the reaction condition space in the first batch (typically 24-96 reactions)
- Sobol sampling maximizes space coverage, increasing likelihood of discovering informative regions containing optima [6]
Execution and Iterative Optimization
Step 3: Execute Initial Batch and Analyze Results
- Prepare reactions using automated liquid handling systems
- Perform reactions under controlled conditions (temperature, atmosphere)
- Analyze outcomes using appropriate analytical methods (e.g., GC-Polyarc-FID for quantification)
- Process data using automated tools (e.g., pyGecko) to extract yield and selectivity metrics [38]
Step 4: Train Machine Learning Model
- Use initial experimental data to train a Gaussian Process (GP) regressor to predict reaction outcomes and their uncertainties
- The GP model captures relationships between reaction parameters and outcomes [6]
Step 5: Select Next Experiments via Acquisition Function
- Apply scalable multi-objective acquisition functions to select the next batch of experiments:
- q-NParEgo: Scalable extension of ParEGO for parallel multi-objective optimization
- TS-HVI: Thompson sampling with hypervolume improvement
- q-NEHVI: Noisy expected hypervolume improvement [6]
- These functions balance exploration of uncertain regions with exploitation of known promising conditions
- Apply scalable multi-objective acquisition functions to select the next batch of experiments:
Step 6: Iterate Until Convergence
- Repeat Steps 3-5 for multiple iterations (typically 3-8 cycles)
- Terminate upon convergence, stagnation in improvement, or exhaustion of experimental budget
- Continuously integrate chemist domain expertise to guide the process [6]
Diagram 1: Autonomous HTE Optimization Workflow (55 characters)
Case Study: Nickel-Catalyzed Suzuki Reaction Optimization
A recent study demonstrates the power of ML-driven HTE for optimizing challenging transformations, specifically a nickel-catalyzed Suzuki reaction [6].
Experimental Setup and Parameters
- Reaction Type: Nickel-catalyzed Suzuki cross-coupling
- Search Space: 88,000 possible reaction conditions
- Batch Size: 96 reactions per iteration
- Optimization Objectives: Maximize yield and selectivity
- Comparison: ML approach versus traditional chemist-designed HTE plates
Results and Performance
The ML-driven workflow identified reactions with an area percent (AP) yield of 76% and selectivity of 92% for this challenging transformation. In contrast, two chemist-designed HTE plates failed to find successful reaction conditions, demonstrating the advantage of the autonomous approach over traditional methods [6]. The optimization campaign efficiently navigated the complex reaction landscape with unexpected chemical reactivity that human intuition had missed.
Table 3: Quantitative Performance Comparison for Nickel-Catalyzed Suzuki Reaction
| Optimization Method | Best Identified Yield (AP) | Selectivity | Number of Experiments | Successful Identification |
|---|---|---|---|---|
| ML-Driven Workflow | 76% | 92% | 576 (6 batches × 96 reactions) | Yes |
| Chemist-Designed HTE Plate 1 | Not specified | Not specified | 96 | No |
| Chemist-Designed HTE Plate 2 | Not specified | Not specified | 96 | No |
| Traditional OFAT | Not achieved | Not achieved | N/A | No |
Advanced Applications and Specialized Methodologies
Flow Chemistry Integration
Flow chemistry serves as a powerful complement to batch-based HTE, particularly for reactions involving hazardous reagents, elevated temperatures/pressures, or photochemistry. The continuous nature of flow systems enables investigation of parameters challenging to address in batch HTE, such as precise residence time control. Furthermore, optimized conditions in flow can typically be scaled without re-optimization by increasing operation time, addressing a key limitation of plate-based approaches [20].
Pharmaceutical Process Development
The Minerva ML framework has been successfully deployed in pharmaceutical process development, optimizing two active pharmaceutical ingredient (API) syntheses. For both a Ni-catalyzed Suzuki coupling and a Pd-catalyzed Buchwald-Hartwig reaction, the approach identified multiple conditions achieving >95 area percent (AP) yield and selectivity. This accelerated process development timelines dramatically—in one case, identifying improved process conditions at scale in 4 weeks compared to a previous 6-month development campaign [6].
The transition from brute-force screening to smart, resource-efficient autonomous workflows represents a fundamental advancement in high-throughput experimentation for chemical reaction screening. By integrating automated experimental platforms with machine learning-driven experimental design and calibration-free quantification technologies, researchers can now navigate complex chemical spaces with unprecedented efficiency. The protocols and case studies presented here provide a roadmap for implementing these advanced workflows, demonstrating their power to accelerate reaction discovery and optimization while conserving valuable resources. As these technologies continue to mature and become more accessible, they promise to transform how chemical research is conducted across academic and industrial settings.
Batch vs. Flow: Validating HTE Performance and Choosing the Right Tool
Benchmarking HTE Batch Against Continuous Flow Chemistry for Reaction Screening
High-Throughput Experimentation (HTE) has emerged as a transformative approach in chemical research and drug development, enabling the rapid screening of reaction conditions and acceleration of discovery timelines. Within HTE frameworks, a fundamental choice exists between conducting reactions in traditional batch systems versus emerging continuous flow platforms [39]. This application note provides a structured comparison of these methodologies, detailing specific protocols and data to guide researchers in selecting the optimal approach for reaction screening within a broader thesis on HTE batch modules.
The core distinction lies in their operational paradigms: HTE batch employs parallel processing of discrete reactions in multi-well plates, while continuous flow utilizes sequential processing of reactions through miniature reactors [39]. Each method offers distinct advantages; HTE batch excels in exploring vast chemical spaces with categorical variables, whereas flow chemistry provides superior control over reaction parameters and enhanced safety for challenging chemistries [40] [39].
Technical Comparison: HTE Batch vs. Continuous Flow
The decision between HTE batch and continuous flow systems depends on multiple technical and operational factors, which are summarized in the table below.
Table 1: Comparative Analysis of HTE Batch and Continuous Flow Systems
| Parameter | HTE Batch | Continuous Flow |
|---|---|---|
| Throughput Nature | High, parallel (e.g., 24-96+ reactions per run) [39] | Sequential, but rapid data collection per profile (e.g., 216 profiles in 90 hours) [41] |
| Ideal Application Stage | Early discovery: library synthesis, scaffold hopping, condition screening with categorical variables [39] | Process development: reaction optimization, kinetic studies, and safe scale-up of specific molecules [39] |
| Reaction Time & Temperature | Typically fixed across a plate [39] | Precisely controlled for each experiment; enables access to novel process windows (e.g., superheating) [40] [39] |
| Heat & Mass Transfer | Limited by vial geometry and stirring | Excellent due to high surface-to-volume ratio [40] [42] |
| Handling of Solids | Straightforward in well plates | Challenging, with risk of reactor clogging [40] [39] |
| Reaction Safety | Limited by contained volume in a single vial | Enhanced safety for hazardous reactions due to small hold-up volume [40] |
| Scale-Up Path | Non-linear; requires re-development in larger batch reactors [39] | Straightforward via "numbering up" or modest geometry adjustments [39] |
| Data for Machine Learning | Generates massive, broad datasets ideal for training models [39] [4] | Effective integration with sequential learning algorithms like Bayesian optimization [39] |
Experimental Protocols
Protocol 1: HTE Batch Screening for Reaction Scouting
This protocol outlines a standard procedure for screening reaction conditions using automated HTE batch modules, ideal for varying catalysts, solvents, and ligands in parallel [18] [39].
Materials & Reagents
- CHRONECT XPR Automated Powder Dosing System: For accurate solid dispensing (1 mg to several grams) of catalysts, bases, and starting materials [18].
- 96-Well Plate Array Manifold: Reaction vessel held in heated/cooled blocks [18].
- Inert Atmosphere Glovebox: Provides an oxygen- and moisture-free environment for setting up sensitive reactions [18].
- Liquid Handling Robot: For precise dispensing of solvents and liquid reagents.
- UHPLC-MS System: For high-throughput analysis of reaction outcomes [43].
Procedure
- Experimental Design: Define the reaction matrix to be tested (e.g., 8 catalysts x 12 solvents).
- Automated Solid Dosing: Program the CHRONECT XPR system to dispense all solid components directly into the respective vials of the 96-well plate. Typical deviations are <10% at sub-mg masses and <1% at >50 mg [18].
- Liquid Addition: Using the liquid handling robot, add the required solvents and liquid reagents to each well under an inert atmosphere inside the glovebox.
- Reaction Execution: Seal the plate and place it in a heated or cooled block for the prescribed reaction time. Note that time and temperature are typically fixed across the plate [39].
- Quenching & Analysis: Automatically quench reactions and dilute samples for analysis by UHPLC-MS to determine conversion and yield.
Protocol 2: Kinetic Profiling Using Segmented Continuous Flow (SPKA)
This protocol describes Simulated Progress Kinetic Analysis (SPKA) in flow, a powerful method for rapidly generating differential kinetic data without running a reaction to completion [41].
Materials & Reagents
- Segmented Flow Platform: Consisting of syringe pumps, a microfluidic chip for segment formation, and a tubular reactor.
- Immiscible Carrier Solvent: A fluorous solvent or inert gas to separate aqueous/organic reaction segments [41].
- Online Spectrometer or HPLC: For instantaneous concentration measurement at the reactor outlet.
- Back Pressure Regulator: To maintain a constant pressure within the system.
Procedure
- Reagent Preparation: Prepare solutions of substrates and catalysts.
- Segment Formation: Use the flow system to create a series of sequential reaction segments with decreasing reagent concentrations, separated by the carrier fluid [41].
- Reaction & Analysis: Pump the segmented stream through a thermostatted reactor coil. Precisely control the residence time and measure the output concentration of each segment as it exits the reactor.
- Data Processing: The instantaneous rate of reaction for each segment is determined from the inlet concentration and the measured conversion at the outlet. A single differential kinetic profile (rate vs. concentration) is constructed from these independent segments, decoupling data collection time from total reaction time [41].
- Interrogating Catalyst Robustness: Collect multiple SPKA profiles at different residence times. Overlaying these profiles reveals catalyst activation/deactivation or product acceleration/inhibition [41].
Workflow Visualization
The following diagram illustrates the key stages and logical relationships in the HTE batch screening workflow.
Diagram 1: HTE Batch Screening Workflow
The Scientist's Toolkit
Key reagent solutions and instrumentation essential for implementing the described HTE and flow protocols are listed below.
Table 2: Essential Research Reagent Solutions and Equipment
| Item | Function/Application |
|---|---|
| CHRONECT XPR Workstation | Automated dispensing of free-flowing, fluffy, or electrostatically charged powders (1 mg to several grams) for HTE workflows [18]. |
| Segmented Flow Platform | Enables high-throughput kinetic experimentation (e.g., SPKA) by isolating reaction mixtures in immiscible carrier fluid segments [41]. |
| Immiscible Carrier Fluids | (e.g., perfluorinated solvents). Creates inert barriers between aqueous/organic reaction segments in flow, preventing cross-contamination [41]. |
| Modular Flow Reactors | Glass or steel microreactors that facilitate excellent heat/mass transfer and enable safe operation at elevated T/P [40]. |
| Process Analytical Technology (PAT) | Inline/online analyzers (e.g., IR, UV) for real-time reaction monitoring in flow systems [39]. |
| High-Throughput UHPLC-MS | Enables rapid analysis of numerous samples from HTE batch plates, providing yield and purity data [43]. |
HTE batch and continuous flow chemistry are powerful, complementary tools. The optimal choice is not one-size-fits-all but is dictated by the project's stage and goals [39]. For broad exploration of chemical space—such as screening diverse catalysts, solvents, and substrates—HTE batch is the superior tool due to its unparalleled parallel throughput [39] [4]. For focused optimization, kinetic analysis, and scale-up of specific reactions—particularly those requiring enhanced heat transfer, safety, or precise parameter control—continuous flow offers significant advantages [40] [41] [39]. An integrated strategy, leveraging HTE batch for initial discovery and continuous flow for subsequent process intensification, represents a powerful paradigm for modern chemical research and development [39].
High-Throughput Experimentation (HTE) has emerged as a transformative paradigm in scientific research, enabling the rapid screening of vast experimental spaces. This is particularly critical in fields like drug discovery and materials science, where the evaluation of thousands of candidate chemicals is necessary to identify viable leads [44]. The core value of HTE lies in its ability to accelerate the "quick win, fast fail" approach, resolving technical uncertainties early in development [44]. This analysis examines the throughput, parameter control, and scalability of three advanced HTE systems: a novel bead-based immunoassay platform (nELISA), high-throughput organ-on-chip (HT-OoC) systems, and automated modules for inorganic synthesis. Performance is quantified and compared to guide researchers in selecting and implementing appropriate HTE batch modules for reaction screening.
Comparative Performance of HTE Platforms
The table below provides a quantitative comparison of three distinct HTE platforms, highlighting their respective throughput, key parameters, and scaling capacity.
Table 1: Performance Comparison of High-Throughput Experimentation Platforms
| Platform | Reported Throughput | Key Controllable Parameters | Scaling Method & Sample Scale |
|---|---|---|---|
| nELISA Immunoassay [45] | - Multiplexing: 191-plex protein panel- Samples: 7,392 samples in <1 week- Data Points: ~1.4 million protein measurements | - Antibody pair specificity (spatially separated on beads)- Detection stringency (via DNA strand displacement)- Bead barcoding (emFRET with 4 fluorophores) | - Scale: 384-well plate format- Throughput: 1,536 wells/day on a single flow cytometer |
| HT-OoC Systems (e.g., OrganoPlate) [44] | - Chips/Plate: 40, 64, or 96 independent microfluidic chips- Assays: Supports perfusion, barrier integrity, transport, and migration assays | - 3D extracellular matrix (ECM) composition- Apical and basolateral perfusion flow rates- Application of compounds and stimuli to specific tissue sides | - Scale: Standard well plate formats (384, 96, 64, 40-well)- Method: Parallelization and batch processing for perfusion and cell injection |
| Automated Synthesis Modules (MAITENA Station) [31] | - Samples/Run: 12 simultaneous syntheses per module- Output: Several dozen gram-scale samples per week | - Precursor solution dispensing volume and sequence- Mixing method and speed (magnetic or vertical stirrer)- Reaction type (sol-gel, Pechini, hydro/solvothermal) | - Scale: Intermediate (400 mg - 1 gram per sample)- Method: Modular liquid-handling units for different synthesis routes |
Detailed Experimental Protocols
Protocol: nELISA for High-Plex Secretome Profiling
This protocol describes the procedure for using the nELISA platform to profile a 191-plex panel of inflammatory proteins from cell culture supernatants, such as those from Peripheral Blood Mononuclear Cells (PBMCs) [45].
Research Reagent Solutions
Table 2: Key Reagents for nELISA
| Reagent / Material | Function / Description |
|---|---|
| CLAMP Beads | Microparticles with pre-immobilized, target-specific capture and detection antibody pairs. The detection antibody is tethered via a flexible, releasable DNA oligo. |
| Displacement Oligo | Fluorescently labeled DNA oligo that performs toehold-mediated strand displacement, simultaneously releasing and labeling the detection antibody upon target binding. |
| emFRET Barcoding Oligos | A set of four dye-conjugated DNA oligos (e.g., AlexaFluor 488, Cy3, Cy5, Cy5.5) mixed in programmable ratios to create unique spectral barcodes for each protein target. |
| Assay Buffer | A buffer matrix compatible with the immunoassay, used for diluting samples and reagents to maintain stability and minimize non-specific binding. |
Step-by-Step Procedure
- Bead Pool Preparation: Combine the spectrally barcoded CLAMP beads, each corresponding to one of the 191 protein targets, into a single master mix in assay buffer.
- Plate Dispensing: Dispense a uniform volume of the bead master mix into each well of a 384-well assay plate using an automated liquid handler.
- Sample Addition: Add the prepared cell culture supernatants or other biological samples to the designated wells.
- Incubation and Antigen Capture: Incubate the plate to allow target proteins in the sample to bind to their cognate antibody pairs on the beads, forming a ternary sandwich complex.
- Washing: Remove unbound proteins and sample matrix by washing the beads, typically using a plate washer.
- Detection-by-Displacement: Add the fluorescent displacement oligo to all wells. This oligo will bind via toehold-mediated strand displacement, releasing the detection antibody from the bead surface and labeling it with a fluorophore. This step occurs only when the target protein is present and has formed the sandwich complex.
- Final Wash: Remove any unbound, free-floating displacement oligo to minimize background signal.
- Flow Cytometric Analysis: Resuspend the beads and run the plate on a high-throughput flow cytometer. The instrument identifies each bead's protein target via its emFRET spectral barcode and quantifies the bound protein by measuring the fluorescence intensity on the bead.
The following workflow diagram illustrates the key steps and underlying mechanism of the nELISA.
Protocol: High-Throughput Screening with Organ-on-Chip
This protocol outlines the use of a multi-well OrganoPlate platform for compound screening on 3D tissue models [44].
Research Reagent Solutions
Table 3: Key Reagents for HT-OoC Screening
| Reagent / Material | Function / Description |
|---|---|
| OrganoPlate | A microfluidic plate (e.g., 40-, 64-, or 96-chip versions) with chips containing channels for ECM gel and perfusion. |
| Extracellular Matrix (ECM) | A hydrogel, such as collagen I, which is pipetted into the gel channel to provide a 3D scaffold for cells. |
| Cell Suspension | Primary cells, cell lines, or ready-to-use organoids suspended in appropriate culture medium. |
| Assay Compounds | Libraries of small molecules, biologics, or other stimuli dissolved in culture medium or buffer. |
| Viability/Cell Death Kit | A fluorescent probe, such as a calcium-AM/propidium iodide mix, for live/dead cell staining and viability assessment. |
Step-by-Step Procedure
- ECM Loading: Using a pipette, fill the designated gel channel in each chip of the OrganoPlate with the liquid ECM solution (e.g., collagen I). Allow the gel to polymerize under controlled conditions (e.g., 37°C for 30 minutes).
- Cell Seeding: Introduce cell suspensions into the appropriate channels. For instance, endothelial cells can be seeded into the perfusion channels to form vascularized tubules, while organoids or other tissue models can be embedded in the ECM gel.
- Perfusion Establishment: Place the OrganoPlate on a rocker platform within a standard cell culture incubator. The rocking motion induces gravity-driven perfusion through the channels, ensuring continuous nutrient delivery and waste removal.
- Culture Maturation: Culture the plates for the required period (e.g., several days to weeks) to allow for the formation and maturation of the microtissues, with medium changes performed as needed.
- Compound Treatment: Add the test compounds to the perfusion inlet of the designated chips. The rocker-based perfusion system will automatically circulate the compounds through the microtissues.
- Endpoint Analysis: At the end of the treatment period, perform endpoint analyses. This can include:
- Live/Dead Staining: Add a mixture of fluorescent viability dyes (e.g., Calcein-AM for live cells, Propidium Iodide for dead cells) directly to the perfusion medium. After incubation, image the chips using a high-content fluorescence microscope.
- Immunofluorescence: Fix the tissues with paraformaldehyde, permeabilize them, and stain with fluorescently labeled antibodies against target proteins of interest, followed by imaging.
- Biochemical Assay: Collect effluent from the outlet channels for analysis of secreted metabolites or proteins.
The following diagram illustrates the integration of the HT-OoC platform within a complete drug discovery workflow.
This comparative analysis demonstrates that modern HTE platforms achieve high throughput via distinct and optimized strategies. The nELISA platform achieves ultra-high multiplexing at the molecular level, fundamentally re-engineering the immunoassay to overcome traditional bottlenecks in protein analysis [45]. HT-OoC systems scale physiological relevance by parallelizing miniature organ models in standardized microplates, enabling complex tissue-level screening [44]. Automated synthesis modules leverage modular hardware and flexible liquid handling to tackle the inherent challenges of inorganic chemistry, providing the intermediate sample scales crucial for materials research [31]. The choice of platform is therefore dictated by the specific scientific question—whether it requires molecular-level multiplexing, tissue-level physiological context, or gram-scale material synthesis. The continued integration of these platforms with AI-driven data analysis and adaptive experimental design promises to further solidify HTE as the backbone of accelerated discovery in biotechnology and materials science.
The biopharmaceutical industry is undergoing a significant transformation in quality assurance, shifting from the traditional Quality by Testing (QbT) to a systematic Quality by Design (QbD) approach [46]. This paradigm shift enables increased operational efficiencies, reduced market time, and ensures consistent product quality through enhanced process understanding and control. The conventional three-batch validation paradigm, while historically useful, presents significant limitations in the context of modern high-throughput experimentation (HTE) and bioprocessing. It often fails to adequately capture process variability and relies heavily on retrospective testing rather than prospective design [47].
The integration of Industry 4.0 technologies—including Artificial Intelligence (AI), Machine Learning (ML), and Digital Twins—is now facilitating a more sophisticated approach to validation [46]. This new framework aligns with regulatory encouragement of QbD and Process Analytical Technology (PAT) initiatives, which aim to build quality into products through rigorous science and data-driven risk management [48]. This article outlines a modernized validation approach that leverages knowledge-based high-throughput screening (KB-HTS) and model-guided development to create more robust, efficient, and predictive validation protocols for bioprocessing and pharmaceutical development.
Knowledge-Based High-Throughput Screening (KB-HTS) for Targeted Validation
Core Principles and Workflow of KB-HTS
Knowledge-Based High Throughput Screening (KB-HTS) represents an innovative strategy that integrates historical knowledge with modern screening technologies to efficiently identify promising compounds. This approach was successfully demonstrated in a study that mined the 'Shanghan Zabing Lun,' an ancient Traditional Chinese Medicine treatise containing over 200 formulae, to rationally select 30 formulae for constructing a 1306-fraction herbal formulae extract library [49]. The KB-HTS workflow systematically integrates historical knowledge with advanced screening technologies, as illustrated below:
Figure 1: Knowledge-Based High-Throughput Screening (KB-HTS) Workflow. This diagram illustrates the sequential process of integrating historical knowledge with modern screening technologies for efficient compound identification.
This approach resulted in the identification of three antiviral lead compounds—ononin, sec-O-β-d-glucosylhamaudol, and astragaloside I—which were found to activate the interferon stimulated response element (ISRE) by triggering p65 phosphorylation and nuclear translocation [49]. The power of KB-HTS lies in its ability to expedite the discovery process by improving dereplication and lead prioritization strategies, making it particularly valuable for novel lead discovery from traditional medicine and other complex systems [49].
HTE Infrastructure and Automation Requirements
The implementation of effective KB-HTS requires sophisticated HTE infrastructure and automation. A comprehensive analysis of AstraZeneca's 20-year HTE implementation journey revealed that successful deployment requires addressing specific technical hurdles, particularly in the automation of solids and corrosive liquids and methods to minimize sample evaporation [18]. Modern HTE laboratories utilize specialized workstation configurations to optimize these workflows:
Table 1: High-Throughput Experimentation Workstation Configuration
| Workstation | Core Function | Key Equipment | Output Metrics |
|---|---|---|---|
| Solids Processing | Automated powder dosing & storage | CHRONECT XPR system, inert atmosphere glovebox | Dosing range: 1mg-several grams; Deviation: <10% at sub-mg, <1% at >50mg [18] |
| Reaction Execution | Automated reaction at gram scale | Liquid handling systems, heated/cooled 96-well arrays | Capability: ~2000 conditions/quarter; Scale: mg levels [18] |
| Screening & Miniaturization | Reaction screening with liquid reagents | Liquid automation, manual pipetting options | Reduced environmental impact, enhanced logistics [18] |
The integration of specialized powder dosing technology has demonstrated significant advantages, including the ability to handle a wide range of solid types (transition metal complexes, organic starting materials, inorganic additives) and a substantial reduction in weighing time from 5-10 minutes per vial manually to less than half an hour for an entire experiment [18]. This level of automation not only increases throughput but also eliminates human errors that were reported to be 'significant' when powders are weighed manually at small scales [18].
Model-Guided Development and Validation
Model Typologies and Applications in Bioprocessing
Model-guided development employs various computational approaches to enhance process understanding and prediction. The selection of an appropriate model depends on the specific application, available data, and required output:
Table 2: Model Typologies and Applications in Bioprocessing
| Model Type | Key Characteristics | Common Applications | Validation Approaches |
|---|---|---|---|
| Statistical & Chemometric | Uses DoE data; describes parameter relationships [48] | Response surface modeling; factor optimization [48] | R², R²adjusted, R²predicted, RMSE [48] |
| Mechanistic | Based on first principles; ODE systems [48] | Unstructured mechanistic models; metabolic network models [48] | Residual analysis, parameter identifiability [48] |
| Hybrid (Semi-parametric) | Combines statistical and mechanistic elements [48] | Complex processes with knowledge gaps [48] | Combination of statistical and mechanistic validation [48] |
| Machine Learning | Data-driven; handles large datasets [46] | Predictive modeling; pattern recognition [46] | Cross-validation; training/test split [46] |
These models form the intellectual backbone of advanced Digital Twins (DTs), enabling bi-directional data communication and facilitating real-time adjustments to optimize bioprocesses [46]. The implementation of DTs, however, faces challenges in system integration, data security, and hardware-software compatibility, which are being addressed through advancements in AI, Virtual Reality/Augmented Reality (VR/AR), and improved communication technologies [46].
Comprehensive Model Validation Framework
Robust model validation is essential for regulatory acceptance and operational reliability. The validation framework should be tailored to the model's purpose, whether that is understanding parameter dependencies or predicting future batch performance [48]. The following diagram illustrates the integrated model development and validation workflow:
Figure 2: Model Development and Validation Workflow. This diagram outlines the comprehensive process from data collection through model development, validation, and regulatory alignment.
Key metrics for model validation include the coefficient of determination (R²) which describes how much variance is explained by the model, and the Root Mean Squared Error (RMSE) which provides a measure of prediction error [48]. To avoid overfitting, it's crucial to use R²adjusted which adjusts for the number of explanatory terms, and R²predicted which uses data not included in model training [48]. The validation should never rely on a single metric but consider multiple measures to comprehensively evaluate model performance.
Integrated Application Notes and Protocols
Protocol 1: Knowledge-Based Antiviral Compound Screening
This protocol outlines the methodology for implementing KB-HTS for antiviral compound identification, based on the successful application in Traditional Chinese Medicine [49].
Materials and Reagents:
- HEK293T cell line carrying luciferase-driven interferon stimulated response element (ISRE)
- Library of 1306 herbal fractions derived from 30 selected formulae
- LC-MS system for hit identification
- Western blot and immunofluorescence equipment for mechanism studies
Procedure:
- Knowledge Mining: Systematically review historical databases (e.g., 'Shanghan Zabing Lun') to identify formulae with reported antiviral activity [49]
- Library Preparation: Prepare a fraction library using standardized chromatographic fractionation of selected herbal formulae
- Primary Screening: Screen the library using the ISRE-luciferase reporter assay in HEK293T cells
- Hit Confirmation: Identify active compounds using liquid chromatography mass spectrometry analysis
- Mechanism Elucidation: Investigate mechanism of action through western blotting for p65 phosphorylation and immunofluorescence for nuclear translocation
- Validation: Confirm antiviral activity through secondary assays and orthogonal readouts
Expected Results: The protocol successfully identified three compounds (ononin, sec-O-β-d-glucosylhamaudol, and astragaloside I) that activated ISRE via p65 phosphorylation and nuclear translocation [49].
Protocol 2: Model Validation for Bioprocess Development
This protocol provides a structured approach for validating models in bioprocessing applications, aligned with QbD principles [48].
Materials and Reagents:
- Historical process data (batch records, quality control data)
- DoE software for experimental design and analysis
- Potential PAT tools for real-time monitoring (e.g., Raman spectroscopy, MIR)
Procedure:
- Define Model Purpose: Clearly articulate the intended use of the model (e.g., prediction, classification, optimization)
- Data Quality Assessment: Evaluate the suitability of modeling data for the intended purpose
- Model Training: Split data into training and test sets; employ cross-validation techniques
- Metric Application: Calculate relevant validation metrics (R², R²adjusted, R²predicted, RMSE)
- Uncertainty Quantification: Evaluate model prediction intervals and confidence levels
- Regulatory Alignment: Ensure validation approach aligns with health authority expectations
Expected Results: A validated model with documented performance characteristics suitable for inclusion in regulatory submissions and operational decision-making.
The Scientist's Toolkit: Essential Research Reagent Solutions
Implementation of knowledge-based and model-guided validation requires specific research tools and reagents. The following table details key solutions and their applications:
Table 3: Essential Research Reagent Solutions for Advanced Validation
| Tool/Reagent | Function | Application Notes |
|---|---|---|
| ISRE-Luciferase Reporter System | Detection of interferon pathway activation [49] | Used in KB-HTS for primary antiviral screening; enables high-throughput readout [49] |
| CHO Edge Platform | Model-guided cell line development [50] | Integrates >2000 genetic elements with computational tools for enhanced protein expression [50] |
| CHRONECT XPR System | Automated powder dosing for HTE [18] | Handles free-flowing, fluffy, granular, or electrostatically charged powders; critical for reproducibility [18] |
| Orthogonal Assay Systems | Hit validation and false-positive elimination [51] [52] | Counterscreen for redox activity, aggregation, assay interference; essential for hit confirmation [52] |
| PAT Tools (Raman, MIR) | Real-time process monitoring [48] | Enables QbD implementation through monitoring of CPPs and CQAs [48] |
The integration of knowledge-based strategies and model-guided validation represents a fundamental shift from the traditional three-batch paradigm toward a more scientific, data-driven approach. This modern framework leverages high-throughput experimentation, advanced modeling techniques, and automation technologies to build quality directly into process design rather than relying solely on end-product testing. The protocols and applications detailed in this article provide researchers with practical methodologies for implementing these advanced approaches, potentially reducing development timelines and improving success rates while maintaining regulatory compliance. As the industry continues to evolve, these strategies will become increasingly essential for tackling more complex targets and modalities, particularly in areas such as biologics development where traditional small-molecule approaches are insufficient.
High-Throughput Experimentation (HTE) has become a cornerstone of modern chemical research and development, particularly in pharmaceutical process chemistry where rapid optimization is crucial. This methodology enables the parallel execution of numerous experiments, dramatically accelerating the exploration of chemical reaction spaces. Two principal implementations have emerged: batch HTE and flow HTE. The strategic selection between these modalities significantly impacts project success, resource allocation, and development timelines. This Application Note provides a structured framework for researchers and drug development professionals to determine the optimal HTE approach based on specific reaction requirements, project objectives, and practical constraints. By establishing clear decision criteria and providing detailed experimental protocols, we empower scientific teams to leverage HTE technologies more effectively within broader reaction screening research initiatives.
Core Principles and Comparative Analysis
Batch HTE: Fundamentals and Characteristics
Batch HTE involves conducting numerous discrete reactions simultaneously in parallel reactors, typically in multi-well plates or vials. This approach mirrors traditional flask-based chemistry but miniaturized and automated for efficiency. In batch systems, all reagents are combined at the beginning of the reaction, and the entire mixture progresses through the reaction sequence as a single unit [53]. A key advantage of batch HTE is its ability to explore diverse, discontinuous condition spaces efficiently, such as testing different catalyst, solvent, and ligand combinations in a single plate [2]. This makes it particularly valuable for initial reaction scouting and optimization where the chemical landscape is largely unknown.
Modern batch HTE implementations often utilize "end-user plates" where reaction components like catalysts are pre-dosed into vials under controlled conditions (e.g., inert atmosphere, refrigeration). Researchers simply add their specific substrates and solvents to initiate the parallel reactions [2]. This standardization streamlines workflow while maintaining flexibility. Batch systems typically operate on scales ranging from microliters to milliliters, conserving valuable starting materials—a critical consideration in early pharmaceutical development where substrates are often scarce [2]. The technology is particularly well-suited for air- and moisture-sensitive chemistries when integrated with glovebox systems [2].
Flow HTE: Fundamentals and Characteristics
Flow HTE, alternatively known as continuous flow chemistry, involves pumping reactants through tubular reactors where chemical transformations occur as the reaction mixture continuously flows through the system [54] [53]. Unlike batch processing where materials are processed in discrete groups, flow systems maintain steady-state operation with continuous input of starting materials and output of products [53]. This fundamental operational difference creates distinct advantages for certain reaction classes and optimization objectives.
A principal technical benefit of flow systems is their superior heat transfer characteristics due to their high surface-area-to-volume ratio [54]. This enables more precise temperature control and facilitates reactions with significant exothermic or endothermic characteristics that might prove challenging in batch reactors. The continuous nature of flow HTE also enables real-time monitoring and adjustment of reaction parameters, allowing researchers to rapidly assess the impact of variable changes on reaction outcomes [55]. Additionally, flow systems generally maintain a low inventory of reactive intermediates at any given time, enhancing process safety particularly when dealing with hazardous or unstable compounds [54] [55].
Strategic Comparison: Batch HTE vs. Flow HTE
Table 1: Comparative Analysis of Batch HTE and Flow HTE Systems
| Parameter | Batch HTE | Flow HTE |
|---|---|---|
| Reaction Scale | Microscale (µL-mL) [2] | Variable, typically continuous streams |
| Process Flexibility | High - independent discrete reactions [2] | Moderate - continuous process parameters |
| Heat Transfer | Lower surface area-to-volume ratio [54] | Superior surface area-to-volume ratio [54] |
| Material Inventory | Full batch committed at start [54] | Low - only small amount under conditions at any time [54] [55] |
| Safety Profile | Pressure relief systems, rupture disks [54] | Inherently safer for hazardous materials [54] [55] |
| Equipment Footprint | Larger relative to throughput [54] | Compact - 10-20% of equivalent batch system [54] |
| Reaction Time Scope | Suitable for various durations | Ideal for reactions requiring precise, short residence times |
| Automation Potential | High for parallel screening [2] | High for continuous processing [55] |
| Capital Investment | Lower initial setup cost [53] | Higher complexity in setup [54] |
| Typical Pharmaceutical Applications | Reaction scouting, catalyst screening, substrate scope [2] | Hydrogenations, photochemistry, electrochemistry, hazardous gas usage [55] |
Table 2: Application-Based Selection Guidelines
| Project Requirement | Recommended HTE Approach | Rationale |
|---|---|---|
| Initial reaction scouting with diverse variables | Batch HTE [2] | Efficiently explores discontinuous condition spaces (catalysts, solvents, ligands) |
| Reactions with significant thermal effects | Flow HTE [54] | Superior heat transfer management for exothermic/endothermic reactions |
| Air/moisture sensitive chemistry | Batch HTE (with glovebox) [2] | Compatible with inert atmosphere manipulation in multi-well plates |
| Processes involving hazardous reagents/intermediates | Flow HTE [54] [55] | Minimal inventory of hazardous materials under reaction conditions |
| Catalyst screening | Batch HTE [2] | Enables parallel testing of multiple catalysts/pre-catalysts |
| Hydrogenation reactions | Flow HTE [55] | Higher catalyst loading, enhanced mass transfer, safer high-pressure operation |
| Limited substrate quantity | Batch HTE [2] | Miniaturized scales (microliter) conserve valuable starting materials |
| Continuous manufacturing development | Flow HTE [55] | Direct scalability from laboratory to production |
Decision Framework and Experimental Protocols
Strategic Selection Workflow
The following diagram illustrates the decision pathway for selecting between batch HTE and flow HTE based on key project parameters:
Batch HTE Experimental Protocol: Suzuki-Miyaura Cross-Coupling
Objective: Efficiently screen multiple reaction conditions for a Suzuki-Miyaura cross-coupling reaction using batch HTE methodology.
Materials and Equipment:
- 24-well glass vial plate [2]
- Pre-dosed catalyst plates (Buchwald Generation 3 pre-catalysts) [2]
- Stock solutions of aryl halide and boronic acid substrates
- Solvent systems (t-AmOH, 1,4-dioxane, THF, toluene with water) [2]
- Base solutions (inorganic phosphates or carbonates) [2]
- Inert atmosphere glovebox [2]
- Heated stirring station
- UPLC-MS system with analysis plate [2]
Procedure:
- Plate Preparation: Retrieve pre-dosed catalyst plate from storage under inert conditions. Six different Pd pre-catalysts are typically employed in a standardized layout [2].
- Substrate Addition: Prepare stock solutions of aryl halide and boronic acid in appropriate solvents. Prioritize solvent selection that ensures complete dissolution of substrates [2]. Using an automated liquid handler, add substrates to each reaction vial.
- Solvent and Base Addition: Add selected solvent systems (4:1 organic/water mixture) and bases to appropriate wells according to experimental design [2].
- Reaction Execution: Seal the plate and transfer to heated stirring station. React at predetermined temperature with continuous mixing for specified duration.
- Reaction Quenching and Analysis: After reaction time elapses, cool the plate and add internal standard (e.g., N,N-dibenzylaniline as DMSO stock) to each vial [2]. Dilute samples into 96-well polypropylene analysis plate for UPLC-MS analysis.
- Data Processing: Analyze using automated tools (e.g., PyParse for UPLC-MS data) to calculate conversion and yield metrics normalized to internal standard [2].
Key Performance Metrics: Product formation (corrP/STD ratio), reaction consistency, and catalyst performance ranking.
Flow HTE Experimental Protocol: Hydrogenation Reactions
Objective: Optimize catalytic hydrogenation reaction parameters using continuous flow HTE system.
Materials and Equipment:
- Fixed-bed flow reactor (e.g., H.E.L FlowCAT) [55]
- Heterogeneous catalysts (50-400 micron particle size) [55]
- HPLC pumps for liquid reagent delivery
- Mass flow controllers for gas regulation
- In-line analytics (FTIR, UV-Vis)
- Back-pressure regulators
- Product collection unit
Procedure:
- Reactor Configuration: Pack fixed-bed reactor with appropriate catalyst (50-400 micron particle size optimal for pharma applications to avoid pressure drops) [55].
- System Conditioning: Pressurize system to target operating pressure (up to 200 bar possible with flow systems [55]) and establish initial flow rates of substrate solution and hydrogen gas.
- Parameter Optimization: Systematically vary key parameters including:
- Catalyst bed length/mass
- Flow rates (liquid and gas)
- Temperature (ambient to 300°C) [55]
- System pressure Monitor output continuously via in-line analytics.
- Steady-State Operation: Maintain each condition set until steady-state output is achieved (typically 3-5 residence times).
- Sample Collection: Collect product fractions at each condition set for off-line validation analysis (e.g., UPLC, GC).
- System Shutdown: Depressurize system following established safety protocols and flush with appropriate solvent.
Key Performance Metrics: Conversion and yield at steady-state, catalyst lifetime, space-time yield, and pressure drop across catalyst bed.
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 3: Key Reagents and Materials for HTE Implementation
| Item | Function/Application | Implementation Notes |
|---|---|---|
| Buchwald Generation 3 Pre-catalysts | Pd-based cross-coupling reactions [2] | Single component provides Pd source and ligand; pre-dosed in end-user plates |
| 24-well End-User Plates | Standardized batch HTE platform [2] | Pre-prepared glass vials with catalysts; stored under inert conditions |
| Fixed-Bed Catalysts (50-400 microns) | Flow HTE hydrogenation and continuous reactions [55] | Optimal particle size to balance pressure drop and reactivity in pharma applications |
| t-AmOH/Water Solvent Systems | Suzuki-Miyaura cross-coupling in batch HTE [2] | 4:1 ratio organic/water mixture common for SMCC reactions |
| Inorganic Phosphates/Carbonates | Base for cross-coupling reactions [2] | Standard bases included in end-user plate designs |
| N,N-dibenzylaniline | Internal standard for UPLC-MS analysis [2] | Enables normalization and reliable comparison between wells |
| Heterogeneous Catalysts (Fixed-bed) | Continuous flow hydrogenation [55] | Enabled by high local catalyst loading in flow systems |
Advanced Applications and Implementation Strategies
Machine Learning-Enhanced HTE
The integration of machine learning (ML) with HTE represents a transformative advancement in reaction optimization. ML algorithms, particularly Bayesian optimization, can dramatically enhance the efficiency of both batch and flow HTE campaigns by intelligently selecting the most informative next experiments based on accumulated data [6]. This approach is especially valuable when exploring complex, high-dimensional reaction spaces where traditional one-factor-at-a-time or grid-based approaches become prohibitively resource-intensive.
In practice, ML-driven HTE begins with initial quasi-random sampling (e.g., Sobol sampling) to achieve broad coverage of the reaction space [6]. Subsequent experimental batches are then selected by acquisition functions that balance exploration of uncertain regions with exploitation of promising conditions [6]. For pharmaceutical applications, this methodology has demonstrated remarkable efficiency, identifying optimal reaction conditions for challenging transformations like nickel-catalyzed Suzuki couplings where traditional approaches failed [6]. In one documented case, an ML-enhanced workflow identified improved process conditions in just 4 weeks compared to a previous 6-month development campaign [6].
Scale-Up Considerations
The ultimate goal of most pharmaceutical HTE campaigns is to identify conditions that successfully translate to manufacturing scale. Here, the choice between batch and flow HTE has significant implications for scale-up trajectories. Batch HTE typically employs miniaturized versions of conventional batch reactors, facilitating direct but not always predictive scaling [2]. In contrast, flow HTE offers more straightforward scale-up through numbering-up (adding parallel units) or limited scale-out (increasing reactor dimensions) while maintaining consistent reaction performance [55].
Flow systems particularly excel in hydrogenation scale-up where they overcome traditional batch limitations. As demonstrated by GSK's implementation of flow hydrogenation, continuous systems enable higher operating pressures (enhancing reaction rates) and eliminate catalyst filtration steps [55]. The smaller equivalent volume of flow reactors allows for safer operation with hazardous reagents and more precise control of process parameters, directly translating to improved product quality in pharmaceutical manufacturing [55].
Hybrid Approaches and Future Directions
The most sophisticated HTE implementations increasingly adopt hybrid strategies that leverage the complementary strengths of both batch and flow methodologies. A common approach utilizes batch HTE for initial broad reaction scouting across diverse chemical spaces, followed by flow HTE for focused optimization of the most promising leads, particularly when enhanced heat transfer, safety, or continuous operation are advantageous.
Emerging trends in HTE technology include the development of integrated systems that combine batch and flow capabilities within a single platform, enabling seamless transitions between operation modes. Additionally, advances in real-time analytics and automated decision-making are accelerating closed-loop optimization systems where experimental results directly inform subsequent condition selection without manual intervention. These developments promise to further compress development timelines and enhance predictive accuracy in pharmaceutical process development.
Conclusion
HTE batch modules have firmly established themselves as an indispensable tool for accelerating reaction discovery and optimization in drug development. By enabling the rapid parallel screening of vast reaction spaces, they dramatically reduce the time from concept to optimized conditions. The integration of machine learning and advanced data analytics is pushing these systems beyond simple screening into the realm of intelligent, autonomous optimization. Looking ahead, the future lies not in a binary choice between batch and flow, but in the strategic combination of both. Hybrid approaches that leverage the strengths of each—using batch for initial broad screening and flow for intensified, scalable process development—will define the next generation of efficient and sustainable pharmaceutical research. This synergy will be crucial for tackling increasingly complex synthetic challenges and delivering new therapies to patients faster.
References
- 1. Practical High-Throughput Experimentation for Chemists [https://pmc.ncbi.nlm.nih.gov/articles/PMC5467193/]
- 2. High-Throughput Experimentation (HTE) Approaches at ... [https://www.domainex.co.uk/news/high-throughput-experimentation-hte-approaches-domainex-advantages-end-user-plates]
- 3. High-Throughput Experimentation (HTE) [https://www.virscidian.com/applications/high-throughput-experimentation]
- 4. Probing the chemical 'reactome' with high-throughput ... [https://www.nature.com/articles/s41557-023-01393-w]
- 5. Quantitative high-throughput screening data analysis [https://pmc.ncbi.nlm.nih.gov/articles/PMC4375054/]
- 6. Highly parallel optimisation of chemical reactions through ... [https://www.nature.com/articles/s41467-025-61803-0]
- 7. Batch reactors [https://www.hte-company.com/en/laboratory-systems/batch-reactors/]
- 8. How to Architect a Modern Data Platform in 2025 [https://www.domo.com/learn/article/how-to-architect-a-modern-data-platform-in-2025]
- 9. Top Quantitative Analysis Tools 2025: Unlock Data Insights [https://airbyte.com/top-etl-tools-for-sources/top-quantitative-analysis-tools-unlock-data-insights]
- 10. 96-Well Plate Dimensions [Standard Microplate] [https://www.wellplate.com/96-well-plate-dimensions/]
- 11. Microplate Dimensions, Working Volumes and Packaging [https://www.revvity.com/ask/microplate-dimensions-working-volumes-and-packaging]
- 12. Inheco Teleshake: Compact shaker for plates for 96 & 384 ... [https://www.inheco.com/teleshake.html]
- 13. Equipment Inventory | Linac Coherent Light Source [https://lcls.slac.stanford.edu/equipment-inventory]
- 14. Teleshake 1536 [https://www.inheco.com/teleshake-1536.html]
- 15. Microwell Plates Market Report | Global Forecast From ... [https://dataintelo.com/report/global-microwell-plates-market]
- 16. PS (Polystyrene) – Chemical Resistance Chart [https://blog.darwin-microfluidics.com/ps-polystyrene-chemical-resistance-chart/]
- 17. Emerging trends in the optimization of organic synthesis ... [https://www.beilstein-journals.org/bjoc/articles/21/3]
- 18. Automation Revolutionizes High Throughput ... [https://chronect.trajanscimed.com/news/high-throughput-experimentation-hte]
- 19. High throughput systems [https://www.hte-company.com/en/laboratory-systems/high-throughput-systems/]
- 20. Flow chemistry as a tool for high throughput experimentation [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d5dd00129c]
- 21. Reaction screening in multiwell plates: high-throughput ... [https://pubmed.ncbi.nlm.nih.gov/33432233/]
- 22. Data-Driven Reagent Selection for Empirical Reaction ... [https://chemrxiv.org/engage/chemrxiv/article-details/68ee3cc2dfd0d042d171671a]
- 23. Recent advances in palladium-catalyzed Suzuki-Miyaura ... [https://www.sciencedirect.com/science/article/pii/S0022328X25000634]
- 24. Advantages and Challenges of Cross-Coupling Reactions ... [https://www.chemical.ai/blog/advantages-and-challenges-of-cross-coupling-reactions-and-recent-progress-in-suzukimiyaura-reactions]
- 25. Applications of organocatalysed visible-light photoredox ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC6122060/]
- 26. Emerging trends in the optimization of organic synthesis ... [https://www.sciencedirect.com/science/article/pii/S1860539725000088]
- 27. Eli Lilly and Company in Collaboration with Strateos, Inc. Launch Remote-Controlled Robotic Cloud Lab | Eli Lilly and Company [https://investor.lilly.com/news-releases/news-release-details/eli-lilly-and-company-collaboration-strateos-inc-launch-remote]
- 28. Lilly launches TuneLab platform to give biotechnology companies access to AI-enabled drug discovery models built through over $1 billion in research investment | Eli Lilly and Company [https://investor.lilly.com/news-releases/news-release-details/lilly-launches-tunelab-platform-give-biotechnology-companies]
- 29. Eli Lilly, Nvidia partner to build supercomputer, AI factory for drug discovery and development [https://www.cnbc.com/2025/10/28/eli-lilly-nvidia-supercomputer-ai-factory-drug-discovery.html]
- 30. Evaluating batch correction methods for image-based cell ... [https://www.nature.com/articles/s41467-024-50613-5]
- 31. Affordable Automated Modules for Lab‐Scale High‐ ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12444737/]
- 32. Bayesian Optimization for Chemical Synthesis in the Era of ... [https://www.mdpi.com/2227-9717/13/9/2687]
- 33. Model: Bayesian Optimisation for Biology | Imperial - iGEM 2025 [https://2025.igem.wiki/imperial/Model]
- 34. Bayesian Optimization of Long-term Outcomes with Online ... [https://arxiv.org/html/2506.18744v2]
- 35. Accelerating cell culture media development using ... [https://www.nature.com/articles/s41467-025-61113-5]
- 36. ReactALL [https://www.crystallizationsystems.com/products/reactall/]
- 37. 生物治疗药 [https://www.wyatt.com/zh-hans/solutions/applications/biotherapeutics-biophysical-characterization-aggregation-quality.html]
- 38. Calibration-free quantification and automated data analysis for ... [https://pubs.rsc.org/en/content/articlehtml/2025/dd/d4dd00347k]
- 39. Flow chemistry or HTE? When machine learning enters the ... [https://www.reactwise.com/news/flow-chemistry-or-hte-when-machine-learning-enters-the-lab-the-best-setup-isnt-one-size-fits-all]
- 40. Batch or flow chemistry? – a current industrial opinion on ... [https://www.sciencedirect.com/science/article/abs/pii/S2211339822000089]
- 41. Enabling High Throughput Kinetic Experimentation by Using ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC10952970/]
- 42. Comparative Study of Batch and Continuous Flow ... [https://www.mdpi.com/1422-0067/24/18/14136]
- 43. Identifying opportunities for late-stage C-H alkylation with ... [https://www.nature.com/articles/s42004-023-01047-5]
- 44. State-of-the-art in high throughput organ-on-chip for ... [https://pmc.ncbi.nlm.nih.gov/articles/PMC12149869/]
- 45. nELISA: a high-throughput, high-plex platform enables ... [https://www.nature.com/articles/s41592-025-02861-6]
- 46. A roadmap for model-based bioprocess development [https://www.sciencedirect.com/science/article/pii/S0734975024000727]
- 47. SOP for Process Validation [https://www.pharmaguideline.com/2012/07/sop-for-process-validation.html]
- 48. About Model Validation in Bioprocessing [https://www.mdpi.com/2227-9717/9/6/961]
- 49. Ononin, sec-O-β-d-glucosylhamaudol and astragaloside I [https://pubmed.ncbi.nlm.nih.gov/31082475/]
- 50. Advancing Bioproduction: Model-Guided Cell Line ... [https://www.bioprocessintl.com/sponsored-content/unlocking-the-potential-of-cho-cells-advancing-bioproduction-with-next-generation-vector-design-and-model-guided-cell-line-development]
- 51. Unlocking High-Throughput Screening Strategies [https://www.evotec.com/sciencepool/unlocking-high-throughput-screening-strategies]
- 52. Hit Validation for Suspicious Minds [https://www.sygnaturediscovery.com/news-and-events/blog/hit-validation-for-suspicious-minds/]
- 53. How Batch Processing Differs From Continuous Flow ... [https://www.generalkinematics.com/blog/batch-processing-vs-continuous-flow/]
- 54. Batch vs. Continuous Process - Flow Chemistry - Kilolabs [https://kilolabs.com/resources/flow-chemistry-vs-batch-chemistry/]
- 55. Batch Versus Flow in Pharma: The upsides of continuous ... [https://helgroup.com/blog/batch-versus-flow-in-pharma-the-upsides-of-continuous-chemistry/?srsltid=AfmBOoqaa1K8JZPENKHL5dtusNqPtAtMoHMnGCLtJKAL5JK1ojXvWYWp]